CTF-PWN做题的思路小记
没有什么是真正的Trick
[toc]
以下内容都是做题的时候遇到的一些知识点,但是由于时间原因,不可能详细记录每道题的详细解法,因此将这些题目的trick进行一个简要的总结。
llvm pass pwn
基本知识
llvm pass pwn假如想上难度,可以非常难,因为非常考验逆向功底,有时候还需要手搓llvm。
这里记录一下运行、调试llvm的基本方法。
首先,题目会给出一个opt和一个题目动态链接库.so。
而最终,我们在本地会运行如下命令:
1 | |
例如:
1 | |
而远程会自动运行该代码。
若题目使用的exp.ll不太复杂,可以直接使用C++编译,则可以直接使用如下命令来从c++代码生成.ll:
1 | |
题目环境
题目会给出不同版本的opt,而根据本人测试,不同版本的opt(即llvm和clang)存在较大差异(包括opt-8 opt-10 opt-12等等)。
因此,这里推荐直接到对应的docker容器来完成整道题目,包括调试等,因此推荐roderick师傅的仓库。
调试时,若是通过c++编写的代码,可以使用如下笔者写的简易脚本run.sh来进行调试:
1 | |
注意基本上每一行都需要改:
- 第一行,修改
clang版本 -ex的第一行,修改动态链接库的名称、参数名称-ex的第二行,断点位置,需要下到一个动态链接库完全加载好的地方。
运行该脚本后,我们会暂停到一个已经加载好动态链接库的地方,此时我们便可以通过动态链接库基地址加上ida中反编译得到的地址来下断点进行调试。
总体思路
首先先要能运行题目。在选择了正确版本的opt(来源于llvm)和clang后,我们需要找到PASS注册的名称。这里可以通过交叉引用__cxa_atexit函数,如下所示:
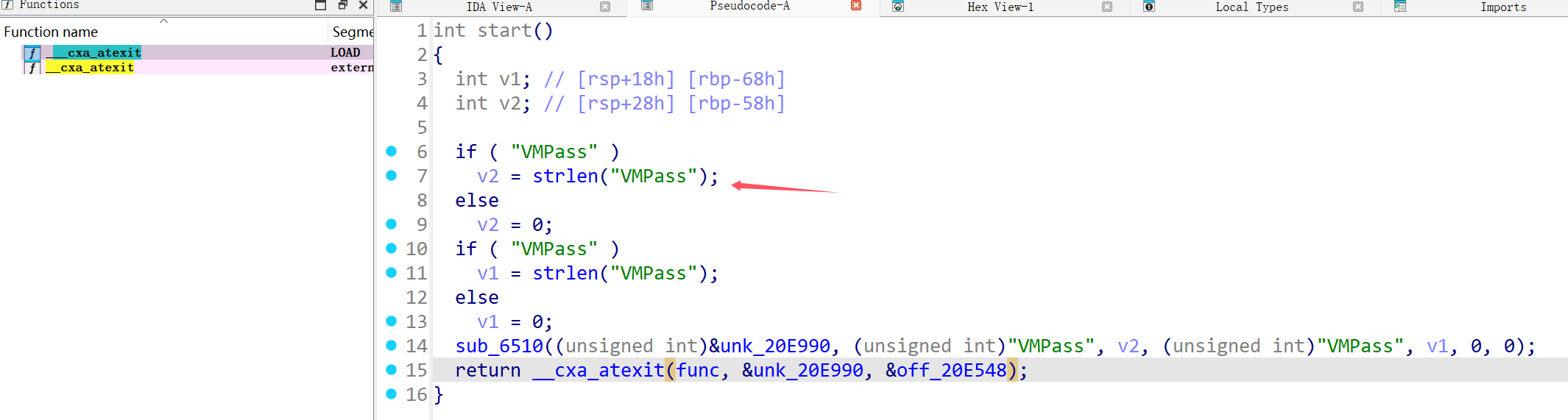
则:
1 | |
上面的-VMPass注册名称就是我们上面找到的。
出题人写的程序是.so文件,而最终我们pwn掉的程序本身是opt。这个程序通常具有如下特点:
- 不开启
PIE Partial RELRO
这就给了我们程序基地址和打got表的机会。
对于一般的llvm pass pwn,出题人一般会选择重写runOnFunction函数,找到该函数的流程可以如下:
- 在
ida中切换到汇编形式 Search - Text,搜索vtable- 最后一个函数一般即为重写的
runOnFunction
对该函数进行逆向,即可写出exp.c来运行llvm虚拟机。例如红帽杯simple-vm如下:
1 | |
父进程使用ptrace监视子进程
西湖遇到的,父进程使用ptrace来监测子进程的系统调用。检测到特定的系统调用才放行,否则将rax设置为-1导致系统调用失败。
不难想到,目前的沙箱做法中ptrace并不是主流的做法,猜测存在缺陷,这里提供一种解决方案:
子进程先调用int 1或者int 3产生中断,随后就可以无视父进程的ptrace的系统调用检测。原因是ptrace无法识别系统调用产生的中断是进入系统调用时还是退出系统调用时,因此手动进行一次中断后,可以导致进入和退出系统调用识别上的错误,导致检测完全失效。推荐可以使用int 1(预期是int3),因为int 1在libc中有int 1; ret 的gadget。
C++异常处理
其实分为很多种情况,这里记录一种大致思路,具体可以看如下两篇文章
溢出漏洞在异常处理中的攻击利用手法-上 - 先知社区 (aliyun.com)
溢出漏洞在异常处理中的攻击手法-下 - 先知社区 (aliyun.com)
只要是异常处理,那必然是存在try-catch块,如下所示:
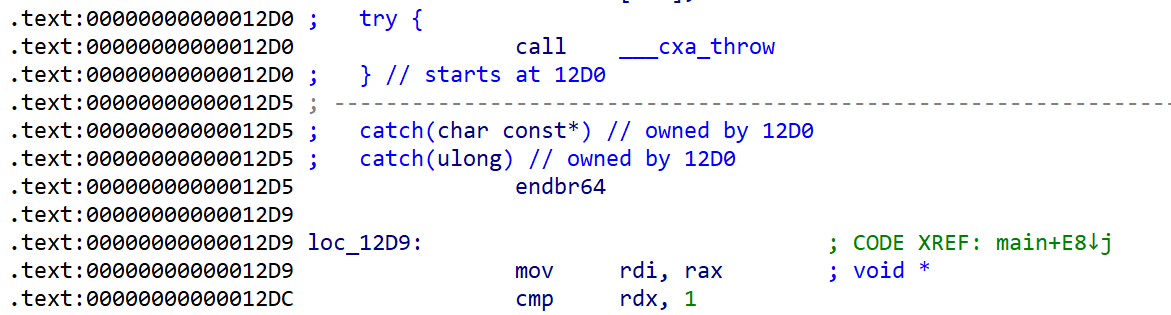
在检测到异常时,程序会抛出异常,并将程序控制流劫持到catch块。
我们可以调试正常情况下,其没有被覆盖时的返回地址。我们劫持该返回地址为任意一个含有catch块的try里面,且地址不为以前一模一样的(可以加一加二加三,多试下),即可将程序控制流劫持到任意的catch块中。例如,上图中可以将返回地址劫持为0x12d1,程序控制流就会被劫持到该catch块0x12d5。总结一下注意的点:
- 劫持到含有
catch块的try,别的cleanup之类的不行 - 劫持到
try的地址不能完全相同 - 多试下,例如把栈上填满合法的地址,观察一下
- 真的多试一下
pwntools中调试子进程
可以通过找到其pid,随后将pid的值加一来进行调试。如下所示:
1 | |
高版本只有UAF无edit的情况下打largebin attack
需要严格的堆风水。
虽然我们可以利用botcake等方法来操作largebin或者unsortedbin,但是仍然难以打largebin attack。
我们可以利用类似于house of spirit的方式来释放伪造的unsortedbin chunk(前提没有清空操作)
例如,我们释放A和B到unsortedbin并合并,再申请一个A+B的chunk将这个合并的chunk申请回来。
此时,我们可以释放B:但这样做的话,会导致下一个chunk的prev_inuse为0,这导致无法再释放A。
因此,我们可以利用如下方式:
- 释放
A和B到unsortedbin并合并 - 申请回合并的
chunk,同时修改原本的B,将其size改小或者改大。注意控制下一个chunk的prev_size即可,最好是伪造出的chunk header。 - 释放
B,该操作不会导致任何已有的prev_inuse被设置 - 释放
A,此时A+B和B都位于unsortedbin。
而若我们将原本的B的size改大,达到A+原本B < 修改B的情况,那么在unsortedbin中会导致,申请时会先切割A+B而不是B。这样就可以踩libc地址到largebin chunk(B)的bk处。若我们不使用该方法,则难以在bk踩出libc地址。
dl_fini:l_addr劫持
在glibc调用exit函数时,函数会经过如下调用链:
1 | |
而_dl_fini中,有如下部分代码:
1 | |
看似很复杂,但实际上逻辑很简单。看这一段:
1 | |
该行计算出最后调用的函数指针数组的地址。
然而,l->l_addr默认情况下为0,而l->l_info[DT_FINI_ARRAY]->d_un.d_ptr默认情况下为.fini_array的地址。
这意味着,默认情况下该部分会执行fini_array部分的函数。
然而,我们可以劫持l->l_addr:将其加上某个偏移,如此我们可以使得执行的函数不再是fini_array,而是加上偏移后的部分的函数,例如可以加上某个偏移使其执行bss上的地址的函数!
tcache伪造size位并分配到任意大小的tcache
这是tache的一个缺陷,根据测试,直到glibc2.38,该trick仍然有效。
我们已知通过house of spirit来释放一个fake chunk的时候,需要保证fake chunk的下一个chunk的size和inuse位合法。
然而,对于tcache,没有任何安全机制来检查下一个chunk的size和inuse。这意味着我们只需要构造一个任意位置的fake chunk,亦或者是合法的chunk但是篡改其size域,即可将chunk释放到我们指定大小的tcache中去。
poc如下:
1 | |
可以看到,我们在chunk a内部伪造了一个fake chunk,没有绕过任何安全检查的操作,直接能够将fake chunk释放到size为0x251的chunk中。
got表绑定前可以通过修改其表项来更改调用函数
如上所述。
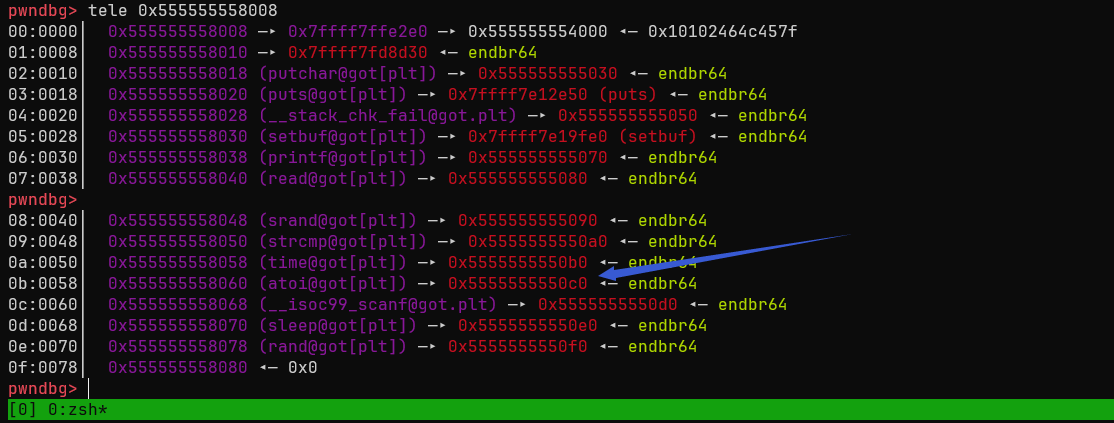
由上可知,atoi函数目前暂未绑定got表,因此,若我们将其最低位更改为0x70(也就是让其变为printf的表项),其便可以寻找到printf的表项,由此aoti函数将变为printf函数。
glibc中rand()预测
实际上只要泄露的数字足够多,完全可以预测:
1 | |
glibc中rand()预测脚本
和上面的方法不太清楚是不是一样的(
主要想记录下这个脚本
1 | |
glibc中rand()精确计算
上面预测的方法需要我们获得非常多的随机数据,而若我们可以泄露libc上的数据时,则无需获得那么多随机数。方法如下:
- 泄露
libc中的randtbl数组,该数组的每个元素都为四字节(_DWORD),第一个元素为RANDOM_TYPE,其他的数为状态数组state。 - 通过状态数组
state即可计算出随机数,即random_value = (state[i] + state[i+1]) >> 1,并更新state[i+1] = (state[i] + state[i+1])。计算完成后,i = i+1。
来个示例如下:
1 | |
因此第一次调用rand()时,结果为:
1 | |
并更新rantbl为如下:
1 | |
第二次调用rand()时,结果为:
1 | |
setcontext + 61便捷修改方式
实际上是SigreturnFrame(),使用bytes(frame)即可
使用mmap代替read读取文件
典型的mmap如下所示:
1 | |
但不能将flags设置为MAP_ANONYMOUS=0x20或者其他值,否则会调用失败。
srand(time(0))绕过(附带Python执行C语言)
time(0)是当前时间戳,其最小单位为秒数,那么在同一秒钟获取该时间戳就好了。
1 | |
exec 1>&0, close(1)
stdin 是0
stdout 是1
stderr 是2
程序使用close(1)关闭了输出流,那么可以使用exec 1>&0将其重定向到stdin,因为这三个都是指向终端的,可以复用。
此外,也可以直接修改掉_IO_2_1_stdout_的_fileno字段为2或者0,也可以再次打开stdout。
格式化字符串close(1)
书接上回。若格式化字符串close(1),主要的解决办法都是有如下几种解决办法:
- 将
_IO_2_1_stdout_的fileno字段改为2 - 将
stdout的指针(一般位于bss)指向stderr
因此,大致可以分为如下几种方式来在格式化字符串中实现:
改printf返回地址到_start
若改printf返回地址到_start,我们便会在栈上留下一个_IO_2_1_stdout_的指针。
再次运行到这里时,我们就可以首先修改该指针末尾使其指向其fileno,将其改为2。即可绕过。
利用magic_gadget改bss上的stdout指针
bss上的stdout和stderr一般后三位不同,因此也难以直接修改。
但是我们可以利用magic_addr来修改bss上的stdout指针为_IO_2_1_stderr_。
有关magic_gadget可以看本文的magic gadget部分内容。
此外需要注意的是,修改后只能用printf而不是puts来泄露内容,因为puts是不走bss上的IO的。
系统调用前六个参数与函数前六个参数
系统调用的参数从上到下以此为:
1 | |
与此同时,函数的前六个参数仅有第四个参数r10和rcx的区别,如下:
1 | |
对开启了PIE的程序下断点
可以通过如下方式在程序0x1000处下断点:
1 | |
高版本申请unsortedbin中chunk的冷知识
某日发现高版本中直接申请下unsortedbin中chunk等同大小的chunk时,会先将该chunk放到tcache,随后申请出来。
这就导致申请回来的chunk含有堆地址(tcache->key),而不是main_arena+xxx。
解决办法是申请一个小一点的即可。
pwntools发送一个EOF
可以用sh.shutdown_raw('send')来发送EOF,效果是让read函数返回0。
但是似乎用了之后也无法得到shell了,这个有没有用呢?不清楚
更新:查看这篇pwntools发送eof信号_pwntools send-CSDN博客
CET安全机制
CET安全机制分为两个,shadow stack和IBT(Indirect Branch Tracking)。
shadow stack
在程序使用call func的时候,会记录下当前的rip,即调用函数的返回地址。在函数退出时会将shadow stack里面的返回地址和栈上的返回地址进行比对,若不一样,则说明返回地址遭到篡改。可以有效防止栈溢出等ROP类攻击方法。
IBT
IBT使得无法任意控制程序执行流到任意位置。在函数开始时,函数会有一个endbr64或endbr32标记。若jmp和call等控制程序执行流的操作没有导向endbr标记,则说明程序执行流可能遭到篡改。
存在格式化字符串漏洞,但是只能利用一次
程序在结束的时候会遍历fini_array里面的函数进行执行,将其劫持为main函数将会重新执行一次main函数。要无限执行,请看下一条。
fini_array劫持无限执行main函数
若只覆盖array[1]为main_addr,那么只会执行一次main函数便会执行下一个array中的函数。
要无限执行某个函数,需要使用这个方式:
1 | |
这是因为默认情况下,fini数组中函数中存放的函数为:
1 | |
而在__libc_csu_fini函数中会调用这两个函数,其执行顺序为array[1] -> array[0]。
修改后,其执行顺序将会变为:
1 | |
从而达到无限执行的目的。
终止条件即只要当array[0]不为__libc_csu_fini即可。
通过fini_array栈迁移来实现ROP
通过上面的无限循环方法执行某个函数时,若该函数可以进行一个任意地址写,那么我们便可以利用上述方式在array[2]处布置rop链。
布置完成后,布置fini_array为如下形式:
1 | |
由于本身执行的函数是存放于array[1]的,因此执行完后会执行array[0]处的leave_ret的gadget,导致rip为ret,然后执行我们布置的rop链。
存在栈溢出,但是只能覆盖返回地址,无法构建ROP链
栈迁移
off-by-one利用
上一个chunk末尾为0x8这种类型,那么通过off-by-one可以任意修改下一个chunk的大小,将其改大,并将其释放,再申请,即可造成chunk的重叠,即被改大的这个chunk和它之后的chunk重叠,那么可以通过修改这个chunk来修改被重叠的chunk。同时也可以将重叠的unsorted chunk释放,打印被改大的chunk,即可泄露libc。
fastbin attack的0x7f
很多时候fastbin attack为了绕开memory corruption (fast),需要使用malloc_hook或者free_hook附近的0x7f来构造一个fake chunk。实际上,size为0x7f的chunk去掉N M P位,也就是0x78,由于最后0x8是在下一个chunk的prev_size字段,那么实际上0x7f的chunk是对应size为0x70的普通chunk,也就是通过malloc(0x60)得到的。
one_gadget环境变量修改(realloc_hook调整栈帧)
one_gadget并不是直接就生效的,而是在一定条件下才生效,如下图所示,constraints部分就是必须满足的条件。
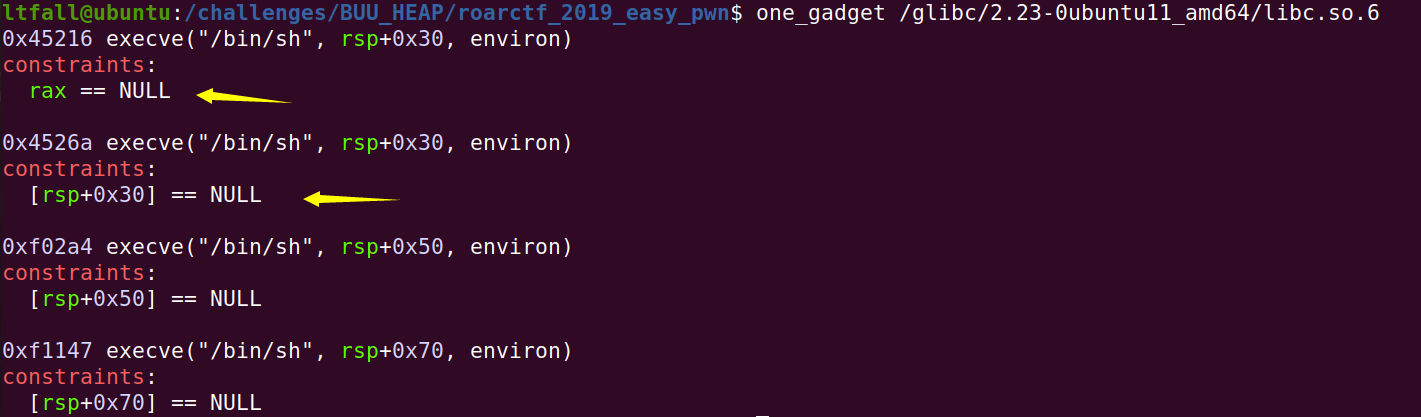
从上面可以看到,若要使用第一个gadgets,那么要满足rax=0;若要使用第二个gadgets,那么要满足[rsp+0x30]=0。然而,多数情况下我们是无法这么轻易地操纵这些寄存器的值的,但是我们可以借助realloc_hook来轻松完成这个操作。
首先,在libc中,__realloc_hook和__malloc_hook是相邻的,这意味着在使用fastbin attack的0x7f的fake_chunk来打__malloc_hook的时候,可以很顺便地打__realloc_hook(__realloc_hook在__malloc_hook前面一个)。__realloc_hook和__malloc_hook类似,程序在调用realloc的时候,同样会检查__realloc_hook,若__realloc_hook里面有值,会跳转到__realloc_hook里面的地址执行。但不同的是,realloc函数在跳转到__realloc_hook之前,还有一系列的push操作,如图所示:
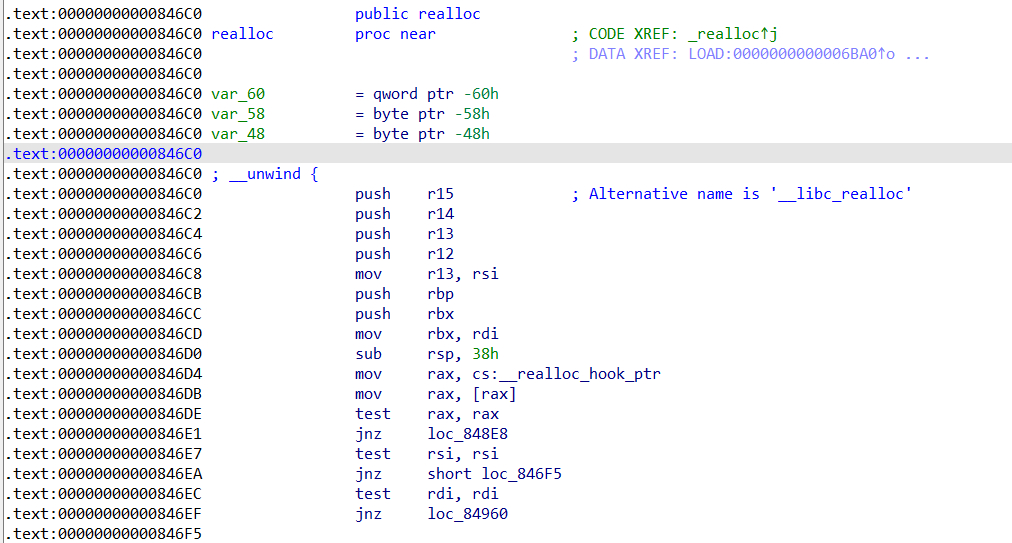
上图是libc里面的realloc函数,可以看到0x846d4处会跳转到realloc_hook,而在这之前有一系列的pop操作。
那么现在考虑:我们将__malloc_hook写为realloc函数的值,并将__realloc_hook写为one_gadget。
那么函数调用链如下:
1 | |
我们将断点打到one_gadget开始的地方(选取的gagdet的满足条件是[rsp + 0x30]=0),即:
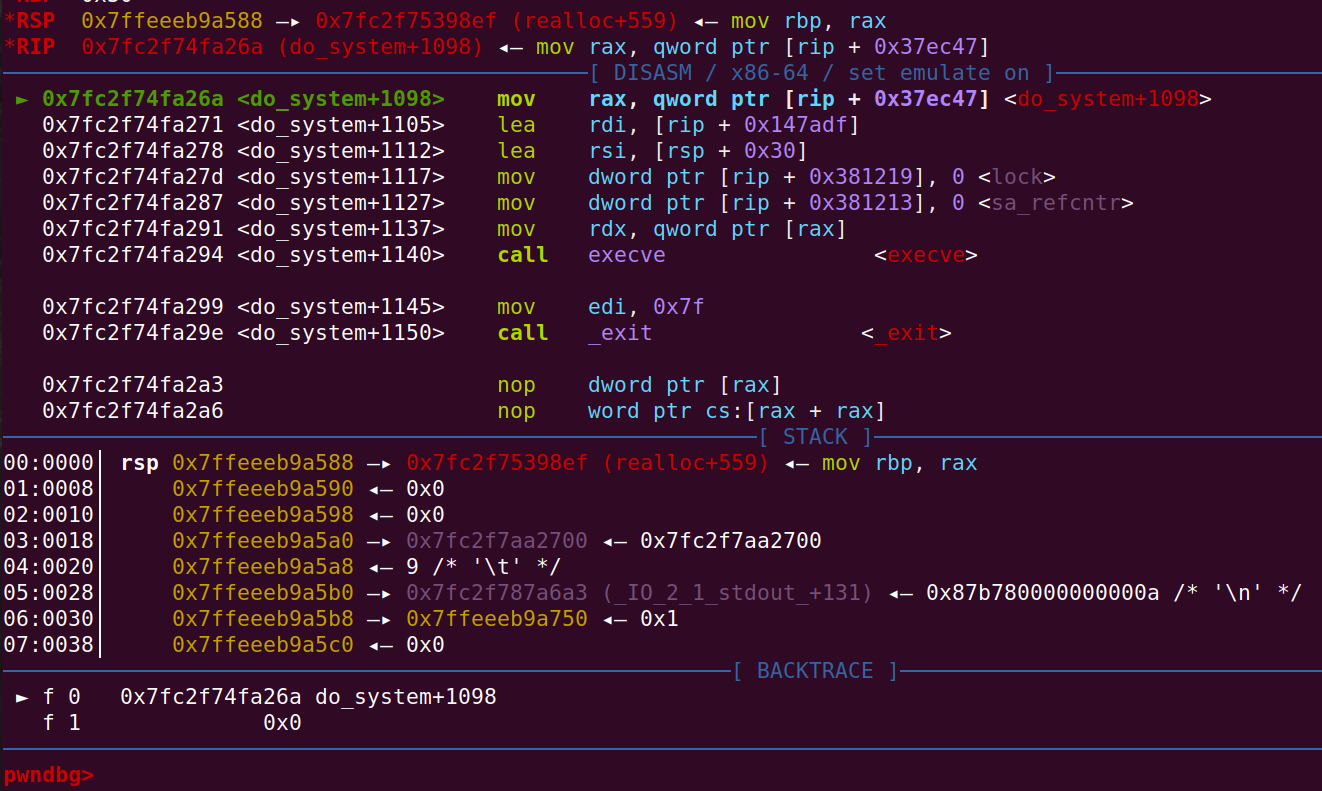
此时rsp的值为0x7ffeeeb9a588,那么查看$rsp + 0x30有:

发现[$rsp + 0x30]不为0,但[$rsp + 0x38]是为0的。
由于在调用__realloc_hook之前,进行了大量的push操作,而push操作会减小rsp的值。因此,若我们少一个push操作,就会使得rsp的值加8,也就使得[$rsp + 0x38]=0了。
翻到上面再看看realloc函数,若我们的__malloc_hook不跳转到realloc函数的开头,而是偏移两个字节的地方,就少了一个push操作了,这样一来整个流程就可以打通,也就满足了one_gadget的条件了!
最后,记录一下realloc函数依次增加多少个偏移的字节可以减少一个push操作:
1 | |
exit_hook(stdlib/exit.c)
实际上这并不是一个真正意义上的hook,因为它实际上是劫持了一个指针而已。
程序在正常执行完毕或者调用exit函数的时候,会经过一个程序调用链:
1 | |
而_dl_fini部分的源码如下:
1 | |
可以看到其调用了__rtld_lock_lock_recursive函数和__rtld_lock_unlock_recursive函数。
实际上,调用这两个函数位于_rtld_global结构体,如图所示:
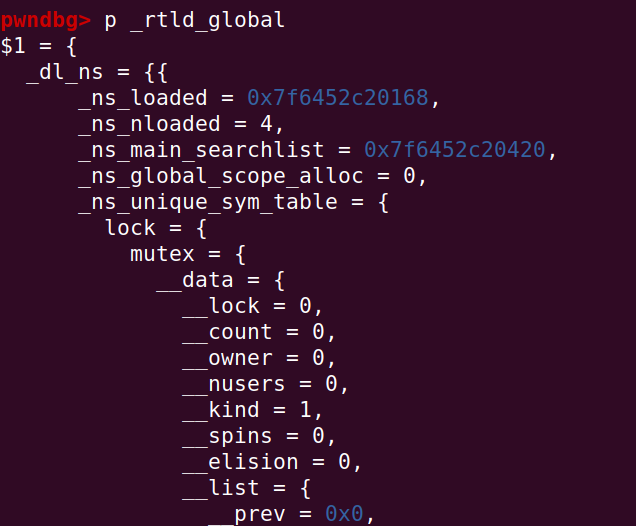
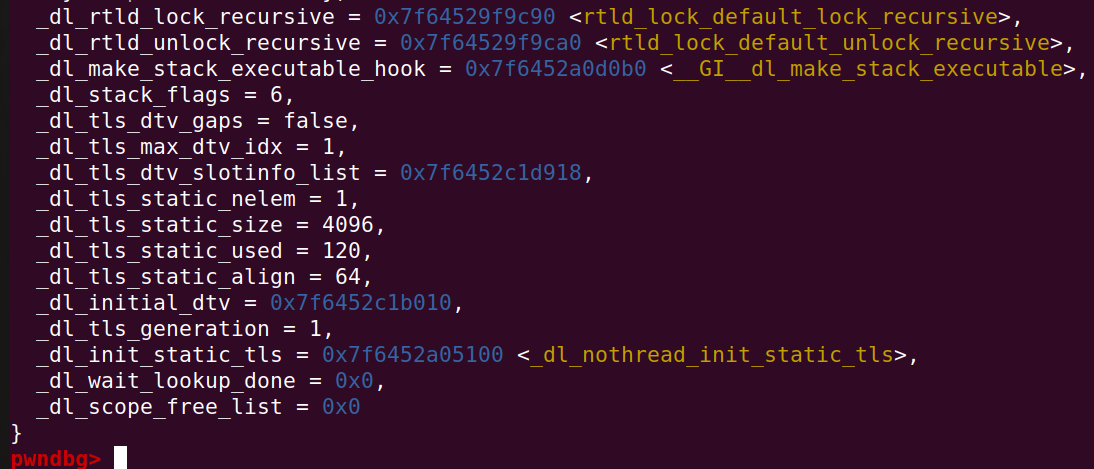
在结构体中可以看到,实际上_dl_rtld_lock_recursive存放了trld_lock_default_lock_recursive函数指针,unlock也是如此。若我们劫持该指针为one_gadget,那么调用exit函数时无论如何也会调用到one_gadget了。
使用如下方式查看该_dl_rtld_lock_recursive的地址:
1 | |

即,我们只需要覆盖该地址处的值为one_gadget即可。需要注意,该exit_hook是ld的固定偏移,而不是关于libc的固定偏移。若能得知libc和ld的偏移,可以使用以下方式算出:
1 | |
此外,若无法打one_gadget,也可以打system,其参数为_rtld_global._dl_load_lock.mutex。推荐通过调试得出。
exit_hook 2
在exit.c的源码中有这样一段:
1 | |
其中,只要exit正常被调用,run_list_atexit就为真,如下所示:
1 | |
这个exit_hook最大的优点是其在libc而不是ld中,缺点是无法传参,只能看运气打one_gadget。
而__libc_atexit是libc.so.6中的一个段,要找它的偏移只需要在ida中查看该段(segments)的地址即可。
或者在gdb中使用如下方式查看:
1 | |
最大的问题是,这种hook在很多版本是不可写的,包括glibc2.23和glibc2.27等。在glibc 2.31-0ubuntu9.2中是可写的,而在glibc 2.31-0ubuntu9.7中又不可写。因此,这种hook并不能保证通用,在适当的时候可以偷家。
exit_hook 3
这是打SCUCTF2023新生赛学到的一个exit_hook。我们知道fini_array会在程序结束的时候被调用。而fini_array是在elf中的,因此在开启PIE时,一定会将fini_array来加上程序基地址来获取到fini_array的实际地址,从而执行里面的函数。因此,**在libc(其实是ld**)中必然存放有code_base,事实上也确实如此。在程序执行fini_array时,首先从_rtld_global._dl_ns[0]._ns_loaded->l_addr中来获取到code_base,也就是程序基地址,接下来再通过该基地址来加上elf中的fini_array的值,通过该指针来执行里面的函数。
因此,若对_rtld_global._dl_ns[0]._ns_loaded->l_addr进行覆盖,便可以起到hook的作用。只需要满足以下式子即可:
1 | |
这里通常情况下可能不太好打one_gadget,也可以打system,调试一下观察rdi,也是一个可以打的值。
获取该hook的地址:
1 | |
最终,执行该hook的代码位于elf/_dl_fini.c中,代码如下:
1 | |
其中汇编代码如下:
1 | |
可以看到rax是数组的i,在i=0时最后执行的即是rsi存放的值指向的值。
在调用这个函数时,该rdi也是可控的,在笔者本次调试为_rtld_global+2312
通过ld来获取程序基地址
1 | |
off by null制作三明治结构
先一句话:大小大,通过小覆盖第二个大的prev_inuse,同时改第二个大的prev size,按照顺序释放两个大,此时三个合并,申请第一个大回来,此时可以通过小来获得libc,再次申请还可以获得重叠指针,进而使用UAF进行fastbin attack或者unsortedin attack等
off-by-null,本部分是在做西南赛区国赛2019年的pwn2总结的,该题目环境是ubuntu18, glibc2.27。
先大致说明一下流程,再详细讲。首先申请三个chunk012,chunk0为large chunk,chunk1为small chunk,chunk2为large chunk。释放chunk0置入unsortedbin,释放chunk1再申请回来(申请末尾为8的,同时写chunk2的prev_size为chunk0+chunk1),此时触发off by null让chunk2认为前一个chunk为free状态。释放chunk2,这会导致chunk2前向合并,将三个chunk合并为一个chunk。申请一个大小为chunk0大小的chunk,会切割这个大chunk为以前的chunk0和chunk1+chunk2,由于chunk1其实并没有被释放而是被合并进来的,因此此时我们可以打印chunk1,即可泄露libc地址,并且再次申请chunk1大小的chunk,会将chunk1切割下来,此时有两个指针都指向chunk1,接下来可以打double free之类的。
画一个图:

如上图,构造如上的形式即chunk0在unsortedbin,chunk1来off-by-null掉chunk2的size末尾使得chunk2认为prev是free的,同时将chunk2的prev_size写成chunk0+chunk1。
此时释放chunk2,会将三个chunk合并成一个并置入unsortedbin。切割下来chunk0,打印chunk1即可泄露libc地址(chunk1虽然合并在里面,但是它并没有被释放)。再次切割chunk1下来,就有两个指向chunk1的指针了。
修复与破局
遗憾的是,从glibc2.29开始,合并时会检查合并的size和prev_size是否相同,传统的三明治也就没有办法使用了。
off-by-null可以通过在泄露了堆地址的情况下构造unlink。注意:
本来small bin和fastbin 正常情况下不会使用unlink。
但实际上,只是因为若是fastbin或者smallbin或者tcachebin,不会设置下一个chunk的prev_size和prev_inuse位罢了。
若我们设置了这两个位,同样可以对fastbin、smallbin、tcache进行unlink,从而构造重叠指针等。
我们同样利用off-by-null和unlink来用三明治类似的思想进行重叠指针的构造。
构造如下图所示:
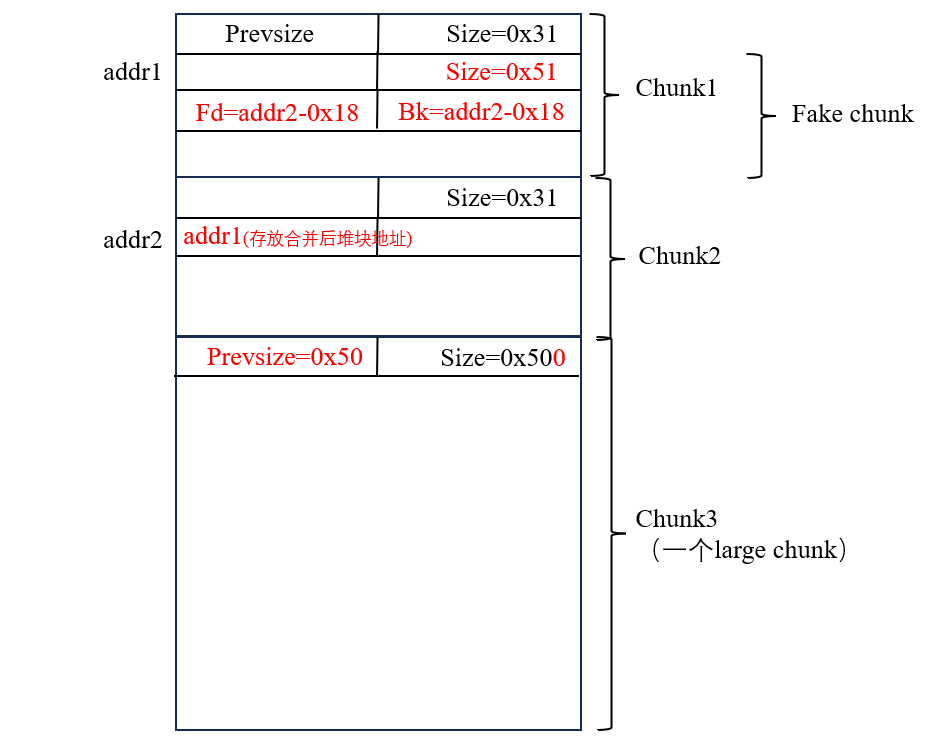
可能比较难以理解,我们详细、分步地解释:
注意,若我没有写对某个堆块free,那么它没有被free。此外,我们需要提前泄露堆地址,保证每个堆块地址可知。
我们有三个chunk,分别是chunk1、chunk2、chunk3,其中chunk3是个large chunk,大小为0x500,另外两个为大小为0x30的chunk。
- 我们通过
chunk2写chunk3的prev_size等于0x50,并off-by-null将chunk3的prev_in_use置为0。 - 正常情况的
unlink我们需要知道一个指向合并后堆块的指针,那么我们在chunk2中写一个合并后堆块的地址,也就是在addr2处写一个addr1。 - 在
chunk1中构造fake chunk,fake chunk的size为fake chunk + chunk2的大小,这里为0x51 fake chunk的fd为addr2-0x18,而bk为addr2-0x10,因为addr2存放的是它自己的地址,是个指向它自己的指针,绕过unlink安全检查。free掉chunk3,此时通过chunk3的prev_size来找到fake chunk,将fake chunk进行unlink,从而导致chunk1-3合并为一个。- 还需要注意的就是,
glibc2.29下,从tcache中获得chunk还会检查对应tcache bin的count是否大于0,大于0才可以申请。因此需要事先释放一个对应大小的chunk。 - 此时三个
chunk会合并到fake chunk的位置而不是chunk1的位置。申请回一个大于fake chunk + chunk1大小的chunk,即可编辑chunk2,获得了chunk2的重叠指针。
off-by-null制作三明治结构-revenge(calloc)
上面我们通过三明治结构可以构造重叠指针。若可以实现多次off-by-null,我们可以在构造重叠指针后,重新将三明治结构再制作一遍,然后三个chunk合并添加到unsortedbin时,可以直接再次delete小的,此时小的会添加到fastbin,然后申请第一个大的,就会使得小的fd和bk被写main_arena+88。这个在使用calloc申请的时候比较有用。
即:两次三明治结构会让保留有重叠指针的情况下让三个chunk再次合并为一个unsortedbin chunk。
off by null之chunk shrink
chunk shrink算是另一种off by null的利用,相比于三明治结构要比较复杂。适用于一些极端情况。
使用方法:小大小三个chunk(不能是fastbin大小),设为abc。b为0x510(例如),在其最末尾写fake prev_size为0x500,释放b置入unsortedbin,通过a进行off by null将b的size变为0x500。申请几个加起来为0x500的chunk,第一个不能为fastbin大小,例如三个为0x88,0x18,0x448,设为def。先后释放d和c,将会导致最开始申请的b和c合并,由此再次申请回d,再申请回e可以获得重叠的e指针。
off by null之无法控制prev_size时
特殊情况,有的时候无法控制prev_size。此时可以考虑使用unsortedbin合并时会自动往prev_size写数据的特性。
如下三个大小为0x100的chunk:
1 | |
先后释放A B C,这会使得A先和B合并,并随之与C合并。而释放B的时候,由于AB合并,C的prev_size便被写了一个0x200,即A B大小之和。
而当我们释放掉三个chunk时,C的prev_size仍然还在。此时我们再先后申请回A B C,C的prev_size不会被清空。
glibc2.23下通过劫持vtable来getshell
程序调用exit时,会遍历_IO_list_all,并调用_IO_2_1_stdout_下的vtable中的setbuf函数。而在glibc2.23下是没有vtable的检测的,因此可以把假的stdout的虚表构造到stderr_vtable-0x58上,由此stdout的虚表的偏移0x58(setbuf的偏移)就是stderr的虚表位置。
通过largebin泄露堆地址
总是忘了在largebin中只有一个chunk的时候它的fd_nextsize和bk_nextsize会指向自身。特此记录,可以通过largebin的bk_nextsize和fd_nextsize来泄露堆地址。
largebin attack后最快恢复链表的方法
个人经验。largebinattack我们一般利用将unsortedbin中的chunk挂入largebin时的分支,我们可以记录在largebin中的chunk还没有被修改bk_nextsize时的fd、bk、fd_nextsize、bk_nextsize四个指针。largebin attack完成后,我们先申请回挂入的unsortebin chunk,然后将largebin中的chunk修改回之前我们记录的四个指针,再申请回即可恢复。
反调试与ptrace
部分题目可能会使用子进程、ptrace的方式来防止调试,一旦调试就会出错。这种情况直接patch掉该部分即可,例如call反调试的函数可以直接跳转到下一条指令转而不执行call。
ptrace在调试时返回-1,非调试时返回0
如标题所示,这也就是ptrace反调试的原理。
canary绕过大全
泄露canary
打印栈上地址,覆盖canary末尾的\x00来直接打印
爆破canary
实际上canary在某些场景确实可以爆破,比如在多进程时,每个子进程的canary都是相同的。因此可以采用one-by-one的方式来对canary进行爆破
劫持__stack_chk_failed函数
canary校验失败时会跳转到__stack_chk_failed函数,因此可以劫持其got表来利用这一点
覆盖TLS中的canary
canary实际上存放在TLS, Thread Local Storage结构体里,校验canary时会通过fs结构体中的值和当前的canary进行比对,若不同则报错。因此可以通过覆盖掉TLS结构体中的值来绕过这个校验。这种绕过方式会根据子进程还是主进程而有略微的不同。
子进程
子进程中该结构体和栈都使用mmap映射到了同一个段中,且其地址比子进程的栈高。因此,可以直接通过栈溢出来覆盖掉tls结构体。即在子进程中若栈存在长度极大的溢出,可以覆盖TLS来覆盖canary。
主进程
主进程中tls结构体仍然位于映射段,但我们知道映射段实际上是基于libc地址的一个偏移。因此,要修改tls结构体基本上不能通过简单的栈溢出,而是可以考虑有libc地址的情况下打一个任意地址写,或者是malloc一个很大的内存,使其通过mmap分配到映射段前面,然后通过堆块溢出来修改tls结构体的值。
归根到底,子进程的tls结构体同样也在映射段上,只是因为子进程的栈也是映射出来的,因此可以直接栈溢出来修改。
覆盖方式
在gdb中,可以通过如下方式查看该结构体:
1 | |
如下所示:
其中的stack_guard就是canary的值。可以在gdb中定位到这个stack_guard的地址,覆盖掉这个值。如:
1 | |
如果上面的方法没有找到canary的存放地址(这是很有可能发生的),可以直接在gdb中寻找tls结构体中canary的地址。
在gdb中可以通过canary命令查看canary的值(有时候也无法得出结果,就在栈上观察一下)。随后,通过gdb搜索内存空间内还有何处有该值。
32位和64位下分别为:
1 | |
栈溢出难以回到主函数重新执行一遍
部分栈溢出尤其是ret2libc等题目时,通常会先泄露libc,再重新回到main函数或者存在栈溢出的函数重新执行一遍以执行ROP。但有的情况下中间会经历太过复杂的操作,因此可以直接使用如下方式:
- 在
ROP链中泄露libc,同时调用程序中的read函数读gadgets到bss段 - 布置
leave_ret,使得栈迁移到bss段执行剩下的gadgets,避免重新执行整个流程
shellcode题目
输入shellcode长度有限
- 可以考虑构造一个
read和ret到rsp,再输入shellcode到rsp执行。栈不可执行的话也可输入rop链 - 要注意:
read的rdx也就是长度不能太长 push不能输入64位立即数- 可以用
push再pop的方式来将rdx里存放rsp的值而不是mov rdx, rsp,这是因为前者字节数更短 - 一个例子如下:
1 | |
限制可见字符
比较常见不必多说,AE64一把梭
1 | |
配置:
1 | |
shellcode限制字符的爆破脚本
我们知道若shellcode类的题目限制了使用的字符为可见字符或字母数字等情况时,可以使用ae64一把梭哈。然而,有的情况的限制更为严格,这种时候往往需要进行手搓shellcode了。
这里是一份shellcode可用字符的爆破脚本:
1 | |
shellcode没有地方写flag内容时,可以用mmap
有时候遇到shellcode段在写好之后又被使用mrotect给禁用写权限的情况。
这个时候可以使用mmap来分配一段内存或者代替read,从而让系统自己决定或者指定一段可写区域。
奇数位置写奇数,偶数位置写偶数
最难的点在于如何构造syscall,因为syscall的字节码为\x0f\x05。
对于这种题目,一般思路我们需要尽快再次构造一个read,避免题目限制给我们带来的影响。
而对于syscall的构造,可以采用如下思路:
- 利用一条指定位置修改的指令,例如
sub [rsi+0x2d], bx来修改出syscall指令。里面的0x2d可以替换为任意奇数。 - 直接通过
call来执行glibc中的函数而不是使用syscall。甚至可以使用glibc中的syscall函数。 - 通过
call构造的时候,可以先从程序的got表里面提取libc的地址来计算。
此外,奇数和偶数可以分别用如下不会干扰shellcode的指令:
- 奇数可以使用
gs、std。 - 偶数可以使用
nop。
最后,总结一些可用指令:
偶数:
1 | |
奇数:
1 | |
奇偶组合:
1 | |
偶奇组合:
1 | |
将global_max_fast打了unsortedbin后链表损坏如何打fastbin attack
unsortedbin attack打了之后链表会损坏,若是要继续申请其它chunk将会出错。
而一种攻击方式是打global_max_fast,使用unsortedbin attack打global_max_fast之后,来打fastbin attack。
然而,unsortedbin attack之后链表损坏,已经难以申请新的chunk了。
解决办法是,在unsortedbin attack时,通过切割,将要进行unsortedbin attack的unsortedbin chunk的大小设置为接下来要进行fastbin attack的大小。如此一来,通过malloc来申请unsorted chunk并触发unsortedbin attack之后,只需要将这个chunk进行free就可以将其置入对应的fastbin了。
通过libc偏移进行堆地址泄露
libc.sym['__curbrk']是堆地址的一个固定偏移
通过FSOP触发setcontext+53
在orw中可以通过FSOP触发setcontext+53,此时rdi是当前正在刷新的_IO_FILE_plus,因此假如将当前的_IO_FILE_plus劫持为堆上的chunk后,即可控制rdi来控制程序执行流。
tcache无法leak时直接修改tcache_perthread_struct
在tcache中含有多个chunk时,tcache存储的指针和tcache_perthread_struct存在固定偏移,可以直接partial overwrite。
tcache中释放tcache_perthread_struct获得unsorted bin chunk
如题
没有leak时通过stdout泄露地址
如果没有leak,那么可以考虑通过打unsortedbin中残留的libc指针,通过partial overwrite的方式来操纵stdout泄露地址。
ROP中的magic gadget
inc
用到的gadget是:
1 | |
由于那道题中的ebp可以随便控制,且got表可以写,因此我们构造一下,使得一直让atol的got表值+1,直到等于system。事实上这道题不是直接用这个gadget来一直+1的,而是使用其来给倒数第二字节一直+1,最低位直接用read来读,以此来减少+1的次数。
ebx的magic gadget
1 | |
如上所示,可以往[rbp - 0x3d]加上ebx的值。若我们可以控制这两个值,可以往任意地址加上一些值。
通常情况下可以配合ret2csu,因为csu可以控制这些寄存器嘛。
例如,可以通过csu和这个magic gadget配合来将alarm的got表的值加五,alarm+5实际上就是syscall。
后记:这个gadget我实测使用ropper找不到。可以用如下方式的ROPgadget来找:
1 | |
malloc_consolidate实现fastbin double free->unlink
大小属于fastbin的chunk被free时,会检查和fastbin头相连的chunk是否是同一个chunk。然而,malloc_consolidate可以将fastbin链表中的chunk脱下来添加到unsortedbin,并设置其内存相邻的下一个chunk的prev_inuse为0。malloc_consolidate可以由申请一个很大的chunk触发。由此,若只能释放同一个fastbin的chunk,可以先free它将其添加到fastbin,然后使用malloc_consolidate将其置入unsortedbin。此时便可以再次free该chunk添加到fastbin,此时一个位于fastbin,另一个位于unsortedbin。申请回fastbin的chunk,在里面伪造一个fake chunk,由于其下一个chunk的prev_inuse被设置,因此可以进行unsafe unlink。不适用于继续fastbin attack,因为另一个chunk不位于fastbin。例题为sleepyHolder_hitcon_2016.
mmap分配的chunk的阈值更改
我们知道malloc一个很大的chunk时会通过mmap来映射到libc附近,而不是top chunk中分配。
然而,当free很大的chunk时,其通过mmap分配的chunk的阈值会改变,改变为free的chunk的大小的页对齐的值。
例如,第一次malloc(0x61a80),会将其以mmap的方式分配到libc附近。我们free这个chunk,此时mmap的阈值将会变为0x62000。我们再次malloc(0x61a80),将会使得其切割top chunk来分配,而不是mmap分配到libc附近。
栈上的字符串数组未初始化泄露libc
某些栈上的字符串若未初始化,可能其中本来存放有一些libc地址,可以直接泄露,或者使用strlen()、strdup()等函数利用。
strcat、strncat等函数漏洞
这些函数会在末尾补一个\x00,有的时候会有奇效(比如覆盖掉下一个变量)
继承suid程序
若一个程序为suid程序,通过这个程序获得shell也可以继承,适用于程序为suid但是flag需要高权限的情况。
可以通过如下方式继承suid权限:
1 | |
对应汇编如下:
1 | |
若存在alarm、close,则可以利用偏移得到syscall
如下所示,alarm+5即可获得syscall,正常情况则没有。close中直接就有
printf中获取到特别长的字符串时会调用malloc和free
如题,因此可以通过这种方式来获得shell:
1 | |
具体多长呢?说不清楚,但是假如printf没有输出那个很长的空白字符串,那就说明执行到malloc_hook里面去了,对吧?
所以可以观察是否有这个输出来判断是否是执行了malloc_hook。
若能使用fstat系统调用,那么可以转32位下获得open系统调用
如题,64位下fstat系统调用号为5,而在32位下系统调用号为5的是open系统调用。
因此可以通过如下方式转32位。
64位和32位系统调用互转
利用retfq进行运行模式的转换。
retfq就相当于jmp rsp; mov cs, [rsp + 0x8],cs寄存器中0x23表示32位运行模式,0x33表示64位运行模式,所以我们只需要构造如下方式就可以实现64到32的模式转换:
1 | |
同理,32位到64位可以通过如下方式:
1 | |
其中的<ret_addr>表示执行retf之后该执行什么,比如可以让push的值为rip+3。
64位转32位时,需要注意rsp是否过长。
需要注意,若转32位,gdb调试时可能会提示:invalid rip xxx,这个时候并不一定有问题,再按一下si,就恢复正常了!
roderick师傅B站录播笔记
工具专题
pwngdb
可以使用
bcall来将断点下到call xx的地方,例如bcall memset会下断点到call memset的地方而不是默认的libc内部。可以使用
tls来查看thread local storagefmtarg可以断在printf时计算format string的indexheapinfoall可以查看每一个线程的heapinfomagic可以打印有用的函数和变量(system、setcontext、各种hook)fp、fpchain分别可以打印IO_FILE结构和IO_FILE的链表chunkinfo可以查看某个chunk的状态,例如是否可以unlink等和上面同理有
mergeinfo
tmux使用
在~/.tmux.conf编写以下配置:
1 | |
便可以通过前缀键`加上\来左右分割屏幕,使用前缀键`加上-来上下分割屏幕,并使用hjkl调整窗口大小。
one_gadget使用
- 并不是一定要满足它写出的条件才可以使用,写出的是充分条件
- 可以使用
one_gadget ./libc.so.6 -n func来找出离某个函数最近的one gadget,在partial overwrite的时候非常有用 - 可以使用
one_gadget --base添加libc地址来输出完整地址
seccomp-tools使用
- 主要是可以通过自己编写如下指令的方式来生成一个带有沙箱的
C语言程序,非常方便
1 | |
通过以下方式直接生成:
1 | |
它会生成#include <sys/prctl.h>方式的沙箱,不会对堆排布造成影响。
关于patchelf
patchelf的路径若过长,可能会导致程序内存空间排布出现问题,尽可能越短越好。
e.g.:
1 | |
也可能会严重影响ld的各种函数,例如tls的
pwntools
抽空去完整读一遍文档吧,很有用
调试
可以使用pwncli调试。这部分去看文档
对于开启了PIE的程序,增加断点的方式可以采用:b *$rebase(0x111)
decomp2dbg
地址,可以将gdb和ida联动,将ida反编译后的内容添加到gdb窗口中从而实现一边调试汇编一边查看ida的源码,它显示的ida的源码甚至拥有你修改过的函数名、变量名,因此也可以直接打印这些变量和名称。
安装好之后ida在plugin-decomp2dbg中监听3662端口,在gdb通过如下方式使用:
1 | |
dl_dbgsym
地址可以通过该工具来完成:当你只有一个libc.so.6文件时,该工具可以自动帮你下载ld并且帮你下载其对应的符号链接,有该工具的话,甚至可以弃用glibc-all-in-one。
pwn_init
可以直接自动完成dl_dbgsym的功能。而且还会给出一些额外的初始化工作,例如将文件设置为可执行等。可以使用pwncli的pwncli init直接完成该操作。
控制mp_结构体来控制tcache分配大小
mp_结构体位于libc中,如下所示:
1 | |
我们可以控制其中的tcache_bins(例如使用largebin attack)为更大的值,从而使得可以释放原本属于largebin大小的chunk到tcache中。
使用如下方式查看其地址:
1 | |
控制mp_结构体来阻止mmap
如上面所讲的mp_结构体,若修改其中的mp.no_dyn_threshold为一个不为0的值,则不再会以mmap的方式来申请chunk。
通过修改chunk的is_mmap位来合并清零chunk
若我们能够修改某个chunk的is_mmap位为1,且满足如下条件时:
- 该
chunk是页对齐的 - 该
chunk的prev_size也是页对齐的(能够整除0x1000)
则当释放该chunk时,该chunk能够和prev_size大小的chunk合并,并将内容全部清零。
由此,我们可以任意控制prev_size的大小,来清零指定的位置。
该方法不能再申请chunk回来,只能达到一个清零的目的。
ret2VDSO
VDSO即Virtual Dynamically-linked Shared Object。为了加快某些常用的函数和系统调用的访问速度,内核将一些常用的函数和系统调用映射到了vdso中,防止经常去系统调用陷入内核态。因此若条件具备,我们可以利用VDSO里面的gadget。这里记录一些小知识:
- 关闭
ASLR时,vdso段相对比较固定 - 可以打
vdso中的rt_sigreturn函数中的gadget进行srop,但是执行rt_sigreturn时栈顶需要和布置的frame有160的偏移,原因未知 - 接上,还需要构造
gs、ss这些不常用的寄存器
通过socket传输数据,例如flag
在VNCTF2022遇到一道题目,题目close(0);close(1);close(2);。而这道题也没办法写shellcode,难以进行侧信道爆破。
此时可以通过socket将flag传输到我们的公网服务器。
首先公网服务器监听10001端口:
1 | |
然后通过socket、connect、write三个系统调用即可传输flag。
socket系统调用
socket系统调用如下:
1 | |
对于IPV4的地址,我们使用如下形式创建一个socket:
1 | |
即:
1 | |
connect系统调用
connect系统调用如下:
1 | |
对于一个IPV4地址,有:
1 | |
若地址为IPV4,那么connect的第二个参数我们一般传输一个struct sockaddr_in,如下所示:
1 | |
其中struct in_addr结构体很简单,如下:
1 | |
即,server_addr在内存中为2字节地址族(小端序),2字节端口(小端序),4字节IPV4地址(小端序),8字节0填充。
1 | |
write系统调用
没啥好说的,直接write(sockfd, buf, size)就可。
例如,整个流程如下所示:
1 | |
house of botcake注意事项
大致流程是对于同一个大小的chunk,先释放7个到tcache,再释放两个同样大小的chunk A B合并到unsortedbin。
申请回一个tcache中的chunk,再释放chunk B,此时tcache中有7个chunk,而第一个即为chunk B;
而此时unsortedbin中有一个chunk A B合并的chunk。
此时,我们通过几次小于上述size的申请,来将unsortedbin里面的chunk申请走,来达到tcache poisoning的目的。
例如上述大小为0x90 (malloc 0x80),那么此时在house of botcake结束后tcache和unsortedbin如下:
1 | |
通过以下方式,将unsortedbin中的chunk完全申请:
1 | |
那么tcache中chunk B的指针即位于chunk 2中,可以进行tcache poisoning attack。
scanf未读入漏洞
有时候会遇到如下形式的代码:
1 | |
然而,若输入-等字符让scanf不读入任何数据,则tmp是一个未初始化的值,那么可以经过printf打印出来,从而泄露栈上的数据。有的时候可以通过该方式泄露libc等重要的值。
堆题没有show的思路小结
通过stdout泄露输出libc地址
若程序赋予了我们修改stdout的能力,且程序会调用相关IO的函数,则可以通过该方式来输出libc的地址
若程序没有调用IO函数,无法通过该方式来输出(__malloc_assert中含有fxprintf)
通过stderr输出敏感信息
我们可以使得程序触发__malloc_assert(),从而触发_IO_2_1_stderr_来输出报错信息。由于触发了__malloc_assert往往会使得程序退出,因此只有flag等敏感信息已经被读取到内存空间后,再直接通过报错输出
stderr的输出和stdout类似,需要将_flags改为0xfbad1887,然后输出_IO_write_base和_IO_write_ptr之间的内容
这是因为__malloc_assert中的__fxprintf函数是IO函数,且其第一个参数传参为NULL的时候会转换为stderr,达到泄露的目的。
通过partial overwrite
不泄露libc地址,直接通过修改unsortedbin的fd指针和got表信息等方式来获得其他libc函数的执行能力。
global_max_fast利用
global_max_fast是main_arena中的一个变量,它的值表示了最大的fastbin chunks的大小。
若我们使用laregbin attack等方式来修改了这个值为一个特别大的值,我们便可以释放一个特别大的chunk到main_arena中的fastbinsY数组中,导致libc中被写入一个堆地址(free掉的chunk)。计算公式为:
1 | |
其中,chunk size表示修改掉global_max_fast后,需要释放的chunk大小。
chunk_addr表示希望写堆地址的地址。
&main_arena.fastbinsY表示fastbinsY的首地址。
使用ret2csu构建参数但不执行函数
有的时候程序里面不含有rdx的gadget,但含有csu的gadget可以使用来控制rdx,而csu必须来call一个存放某个函数的地址(通常是got表),若我们不含有这样的地址,则难以使用csu。
此时可以通过call一个指向_term_proc函数的地址来完成这个操作。_term_proc如下所示:
1 | |
注意,在csu中我们的call需要传递一个执行_term_proc函数的指针而不是其本身的地址。这个地址可以在LOAD段找到:
1 | |
如上所示,0x600e50处存放了一个指向_term_proc的指针。因此可以通过call这个0x600e50来达到csu仅设置寄存器的值而不直接调用函数的目的。
使用ida导入C语言结构体 & protobuf解析
复现国赛strangeTalkBot的时候学到的。
编辑头文件,注释不需要的部分
例如,我需要导入protobuf的结构体,那么我首先需要编辑/usr/include/下的文件,这是C语言include的默认文件夹。
以protobuf的结构体为例:
编辑/usr/include/protobuf-c/protobuf-c.h,注释如下部分:
1 | |
我们需要注释所有无关部分。(完成后记得恢复!)
ida中导入文件
左上角File -> Load File -> Parse C header file ,选择刚刚编辑好的头文件,导入。
将导入的文件添加到结构体
刚刚我们只是导入了这些变量,没有将他们设置为结构体。
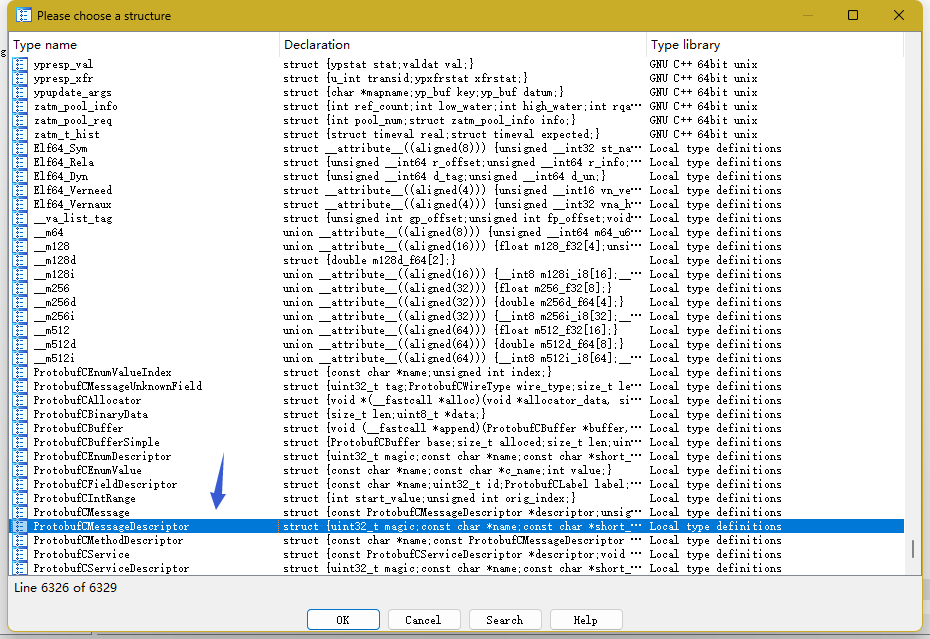
按下shift + F9打开structure页面,添加结构体,可以用如下两种方式:
按下
insert如果你没有
insert键,鼠标右键空白部分,点击add stru type。
接下来点击add standard structure,选择要导入的结构体即可:
应用到数据
鼠标移动到你认为是该结构体的地址的起始处,如图所示:
点击ida左上角的edit,struct var,选中要应用的结构体即可,如下所示:
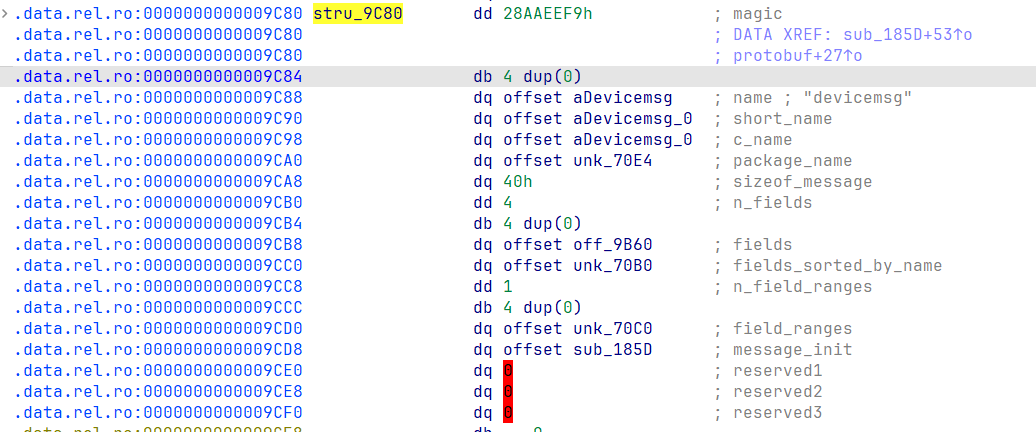
从图中可以看到,其proto的结构体名称叫做devicemsg。观察图里面的fields,可以定位到每个字段的结构体。
字段的数量为n_fileds指示的个数。
接下来,通过同样的方式,可以应用ProtobufCFieldDescriptor结构体到数据部分,如下所示:
可见,这大大帮助我们减少了逆向的难度,例如type等字段已经被设置为其变量名。
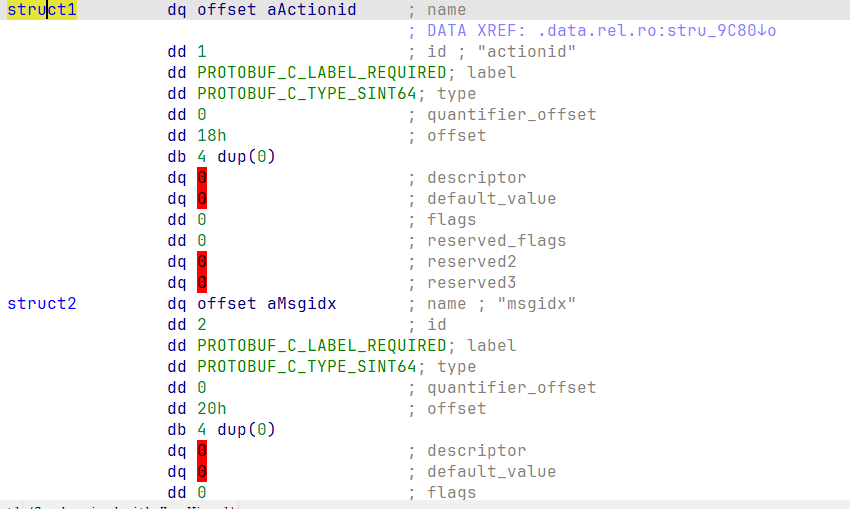
protobuf中有如下字段:
optionalrequiredrepeateadnone,根据我的测试,直接写成optional没问题
protobuf的逆向
逆向完成后,就可以根据图里面的信息,写出protobuf的定义。可以根据是否含有default_value来得知protobuf的版本。若为protobuf2,则含有default_value,若为protobuf3则不含有。
例如上面图中可以得出:
1 | |
(下面是我在另一个题写的,虽然名称不一样,但实际上没啥区别)
随后,即可在命令行,通过如下方式来生成python版本的prorobuf结构体:
1 | |
在此处,我们运行完成后生成的代码名称为bot_pb2.py。我们便可以在exp中导入该文件:
1 | |
随后即可编写如下函数:
1 | |
利用该函数,即可构建正确的输入。
protobuf的逆向之pbtk
只能说有的时候是可以用的。这是github上的一个项目。
我将其下载到了~,便可以通过python3 ~/gui.py来运行pbtk的图形界面。即可通过图形界面操作来逆向得到protobuf。但是并不是每个这样的程序都可以用。
writev系统调用
可以代替write。其中:
1 | |
由此,例如我需要输出0x80000处的长度为0x100的数据,我可以先在堆上构造这个iovec结构体:
1 | |
假设构造的这个payload位于地址heap_base + 0x360,那么使用writev如下即可:
1 | |
libc任意地址写0:通过_IO_buf_base任意写
在glibc题目中,有时候题目会给一个glibc任意地址写一个0,例如whctf2017_stackoverflow,以及r3ctf_2024的Nullullullllu。
此时我们可以考虑写_IO_2_1_stdin_的_IO_buf_base。
先说原理。当我们调用scanf函数时,最终会执行如下函数:
1 | |
可以看到,实际上就是一个read,起始位置为_IO_buf_base。而_IO_2_1_stdin_的原本值可能就是_IO_2_1_stdin_附近的值,因此若我们写_IO_buf_base的最低字节为0,那么我们很有可能可以**让_IO_buf_base和_IO_buf_end之间包括_IO_buf_base**,如果满足,我们便又可以控制_IO_buf_base,并使其指向任何我们想要写的地方,完成一个任意地址写!
而要执行刚刚代码块中的那一行函数,需要绕过以下条件:
1 | |
因此,我们还需要让_IO_read_end等于_IO_read_ptr。
那么如何完成这个操作呢?下面我以题目中的情景举例:
在题目中,我覆盖掉_IO_buf_base的最低字节为0后,我控制到的是_IO_write_base开始的地方,我填充了0x18个字符a,并写_IO_buf_base为__malloc_hook,写_IO_buf_end为__malloc_hook + 8。因此,倘若满足条件,我下一次scanf函数就可以往__malloc_hook写入我想写入的值。
1 | |
然而,我们注意到此时_IO_read_ptr和_IO_read_end的状态:_IO_read_end > _IO_read_ptr。因此scanf会正常获得数据,而不是往__malloc_hook写入数据。
而题目中有IO_getc(stdin);函数供我们使用。该函数本意是清除缓冲区中scanf留下的换行符,而经过我们实测,该函数可以使得_IO_read_ptr的值+1。因此,在上述_IO_2_1_stdin_的结构体中,我们只需要执行0x28次IO_getc(stdin),即可使得_IO_read_ptr = _IO_read_end!
除了IO_getc(stdin)函数,getchar()也有同样的作用。
此外需要注意:
scanf正常情况下我们通过sendline来输入,因为正常情况下scanf以换行符为分隔。- 而我们往
_IO_buf_base输入时,使用send,不需要换行符。
mp_.tcache_bins攻击
介绍
这里先介绍一下mp_.tcache_bins,想快速知道利用方式的师傅可以直接到利用方式小节。
首先咱们需要将mp_.tcache_bins和#define TCACHE_MAX_BINS 64做区分:
- 前者是
mp_结构体里的一个变量,可写,可以在gdb里使用p mp_来查看其结构体 - 后者是源码中一个宏定义,我们毫无疑问是无法修改的
而若我们调用malloc,其会经历如下流程:
1 | |
能看到,TCACHE_MAX_BINS只有在mp_结构体初始化时对其进行赋值,而后面glibc运行时完全基于mp_.tcache_bins进行利用。
再详细查看malloc利用流程,可以看到,malloc任意一个大小时,其都会被先当作tcache,计算出其tc_idx。而当tc_idx小于mp_.tcache_bins时,就会将该chunk当作tcache中的chunk,进而从tcache_perthread_struct中的entries中指定的地址中取出。
由此,正常情况下,mp_.tcache_bins为64,因此只有size小于等于0x410会经历上述流程。
但若我们攻击了mp_.tcache_bins,改变其值为一个非常大的值(例如largebin attack),那么在申请更大的chunk时,便会同样先计算其tc_idx,而此时tc_idx将小于mp_.tcache_bins,从而判定其属于tcache。此时只要其对应的count大于0,那么我们便可以将原本tcache_perthread_struct下面的一个chunk的内容也当作entries部分,合理控制上面的值可以达到任意地址写的目的。
利用方式
假设原本tcache_perthread_struct如下所示:
1 | |
在假设我们已经控制了mp_.tcache_bins为特别大的值,那么:
count和entris的起始位置不变,但现在可以越界写
这意味着,上面第一个chunk中的0x55555555b2a0处的内容将会被当作是tcache_perthread_struct.entries的内容,经过计算刚好为size等于0x440时的内容。
而其count,只要释放一个size为0x20的地方,即可将entries中为0x20的地方(起始处)写上一个值,而该值又被tcache_perthread_struct的count来越界读,将该值误认为是0x420-0x440的count。因此,只要直接申请size=0x440的chunk,即可申请到我们可控的第一个chunk中的内容。
总结如下:
- 控制
mp_.tcache_bins为大值 count和entris的起始位置不变,但现在可以越界写- 释放
size为0x20的chunk,这使得0x420-0x440的count不为0 0x420-0x440对应除了tcache_perthread_struct的第一个chunk中的内容,该内容可控- 将其内容布置为想要申请的地方即可任意地址申请
查表
地址表
左边为申请的chunk,右边为实际对应的地址
| chunk size | address |
|---|---|
| 0x420 | 0x280 |
| 0x430 | 0x288 |
| 0x440 | 0x290 |
| 0x450 | 0x298 |
| 0x460 | 0x2a0 |
| 0x470 | 0x2a8 |
| 0x480 | 0x2b0 |
| 0x490 | 0x2b8 |
| 0x4a0 | 0x2c0 |
| 0x4b0 | 0x2c8 |
| 0x4c0 | 0x2d0 |
| 0x4d0 | 0x2d8 |
| 0x4e0 | 0x2e0 |
| 0x4f0 | 0x2e8 |
| 0x500 | 0x2f0 |
| 0x510 | 0x2f8 |
| 0x520 | 0x300 |
| 0x530 | 0x308 |
| 0x540 | 0x310 |
| 0x550 | 0x318 |
| 0x560 | 0x320 |
| 0x570 | 0x328 |
| 0x580 | 0x330 |
| 0x590 | 0x338 |
| 0x5a0 | 0x340 |
| 0x5b0 | 0x348 |
| 0x5c0 | 0x350 |
| 0x5d0 | 0x358 |
| 0x5e0 | 0x360 |
| 0x5f0 | 0x368 |
| 0x600 | 0x370 |
| 0x610 | 0x378 |
| 0x620 | 0x380 |
| 0x630 | 0x388 |
| 0x640 | 0x390 |
| 0x650 | 0x398 |
| 0x660 | 0x3a0 |
| 0x670 | 0x3a8 |
| 0x680 | 0x3b0 |
| 0x690 | 0x3b8 |
| 0x6a0 | 0x3c0 |
| 0x6b0 | 0x3c8 |
| 0x6c0 | 0x3d0 |
| 0x6d0 | 0x3d8 |
| 0x6e0 | 0x3e0 |
| 0x6f0 | 0x3e8 |
| 0x700 | 0x3f0 |
| 0x710 | 0x3f8 |
| 0x720 | 0x400 |
| 0x730 | 0x408 |
| 0x740 | 0x410 |
| 0x750 | 0x418 |
| 0x760 | 0x420 |
| 0x770 | 0x428 |
| 0x780 | 0x430 |
| 0x790 | 0x438 |
| 0x7a0 | 0x440 |
| 0x7b0 | 0x448 |
| 0x7c0 | 0x450 |
| 0x7d0 | 0x458 |
| 0x7e0 | 0x460 |
| 0x7f0 | 0x468 |
| 0x800 | 0x470 |
size表
| chunk size count | chunk should free | addr |
|---|---|---|
| 0x420 - 0x450 | 0x20 | 0x90 |
| 0x460 - 0x490 | 0x30 | 0x98 |
| 0x4a0 - 0x4d0 | 0x40 | 0xa0 |
| 0x4e0 - 0x510 | 0x50 | 0xa8 |
| 0x520 - 0x550 | 0x60 | 0xb0 |
| 0x560 - 0x590 | 0x70 | 0xb8 |
| 0x5a0 - 0x5d0 | 0x80 | 0xc0 |
| 0x5e0 - 0x610 | 0x90 | 0xc8 |
| 0x620 - 0x650 | 0xa0 | 0xd0 |
| 0x660 - 0x690 | 0xb0 | 0xd8 |
| 0x6a0 - 0x6d0 | 0xc0 | 0xe0 |
| 0x6e0 - 0x710 | 0xd0 | 0xe8 |
| 0x720 - 0x750 | 0xe0 | 0xf0 |
| 0x760 - 0x790 | 0xf0 | 0xf8 |
| 0x7a0 - 0x7d0 | 0x100 | 0x100 |
| 0x7e0 - 0x800 | 0x110 | 0x108 |
通过libc地址泄露ld地址
有时候远程的ld偏移和本地是不一样的。因此,在条件允许(例如我们有任意地址读)的情况下,我们最好通过libc来泄露ld地址。
此时可以查看:
1 | |
静态编译恢复符号
有时候还是有用的。使用Finger即可,目前我在IDA8.3中装了。