经典文章阅读:Understanding glibc malloc
对经典文章Understanding glibc malloc的阅读笔记&夹带自己理解的翻译
[toc]
内存的管理方式有许多种,例如:
1 | |
本文将只对glibc malloc进行讲解,其他的内存管理方式将留到以后进行讲解。让我们开始吧!(本文讲解的内存管理方式基于此处)
发展历史
实际上,ptmalloc2是由dlmalloc的源代码fork而来的,并在dlmalloc的基础上添加了线程的支持,最终2006年发布。这之后,ptmalloc2这一内存管理方式被集成到了glibc中,这之后glibc开始自己对malloc内存管理方式进行修改。因此,目前ptmalloc2内存管理方式和glibc的malloc实现已经有着不小的差距了。
系统调用
如此所示,malloc内部有两种系统调用,即brk和mmap。
线程
在linux的早期版本,dlmalloc才是其默认的内存管理方式,但由于ptmalloc2添加的线程支持,这之后ptmalloc2才成为了linux的默认内存管理方式。线程能够改善内存分配的性能,也就是说,线程的支持能够改善应用程序的性能。在dlmalloc中,当两个线程同时调用malloc的时候,只有一个线程能够进入临界区修改数据,但这个时候操作系统中的空闲内存又是所有线程共享的。因此,内存分配问题在多线程的应用程序中占用了大量时间,造成程序的应用性能下降。在ptmalloc2中,当两个线程同时调用malloc的时候,内存将可以被立即分配,因为每个线程都维护了一个独立的heap,这些heap的空闲内存也是独立的。这个用于为每个线程维护独立的heap和空闲内存的东西就叫做线程arena。在ptmalloc2中,这个“空闲内存”也就是bin。
Example:
1 | |
输出结果分析:
在调用malloc之前:
我们的程序会输出程序进程对应的pid。我们可以访问linux下的/proc/[pid]/maps来查看其内存空间的分配。在下面的输出中,我们可以看到,目前是没有任何heap被创建的,而由于thread1还没有被创建,因此输出中可以看到也没有线程的栈空间出现。
1 | |
主线程调用malloc之后:
此时,我们从下面的输出中可以看到,heap段已经被创建了,且其范围为0x0804b000-0x0806c000,即大小为132kb。这说明这里的堆内存是由brk系统调用来创建的(不懂的可以看上面系统调用那里提到的那篇文章)。注意,用户只申请了1000bytes的内存空间,但操作系统仍然创建了132kb的堆内存。这一段连续的内存区域就叫做arena。以后的内存申请都会使用该区域,直到该区域的内存被分配完为止。有的师傅可能会想,那假如这个arena的内存分配完了的时候怎么办呢?此时,arena可以再通过中断的方式来增加内存。类似地,若top chunk处的空闲内存过大,arena也可以通过这种方式来缩小。
(top chunk是arena中顶部的一个chunk,我们接下来还会进行详细的讲解)
1 | |
主线程调用free之后:
在下面的输出中,我们可以看到,即使用户刚刚申请的内存已经被释放了,刚刚通过brk系统调用获得的132kb的内存并没有被立即释放。此时,刚刚释放的1000bytes的内存空间被释放给了glibc中叫做bin的地方(可以理解为Windows系统中的回收站)。我们前面提到,每个线程都拥有自己的arena,因此我们刚刚释放的1000bytes实际上是放入了main arena的bin中。接下来,若用户需要申请内存,那么glibc将不会从arena中给用户一块新的内存,而是从bin中取出一块内存来给用户使用。只有bins中不含有空闲的内存块时,glibc才会从arena中给用户分配内存。
1 | |
thread1调用malloc之前:
观察代码,我们创建了一个子线程,并且让它执行代码中的threadFunc函数。在子线程刚刚创建,还没有调用malloc的时候,我们查看它的内存空间如下。可以看到,thread1的heap空间目前还没有创建,但它的栈空间已经创建好了。
1 | |
therad1调用malloc之后:
从下面的输出中我们可以看到,thread1的heap空间已经创建好了,且其位于内存的映射区域,即0xb7500000-0xb7521000处,大小也为132kb。这说明这一段内存是通过mmap系统调用来生成的(记得前文说过main arena是通过brk系统调用来生成的吗)。这里同样的,尽管用户只申请了1000bytes,但是操作系统仍然分配了1MB(0xb7500000-b75600000)的内存空间。在这1MB的内存空间中,只有132KB的内存空间有读写权限,这个部分就是thread arena。
1 | |
thread1调用free后:
在thread1调用free后,我们可以看到这段free掉的1000bytes内存空间同样没有还给操作系统。事实上,这段内存空间被释放给了thread arenas bin。
1 | |
Areana
Arena的数量
在上面的例子中,主线程包含了一个主arena,而thread1包含了一个thread arena。那么是否一个线程一定和一个arena一一对应呢?答案是否定的。举个例子,一个程序可以有非常多的线程,甚至多于操作系统拥有的cpu的核心数量,那么这种情况下给每个线程都分配一个arena非常浪费。因此,一个应用程序的子线程arena的数量限制与系统中的cpu核心数相关,如下所示:
1 | |
注意,主线程一定有自己的main arena,因此总的arena数量要在此基础上+1
Arena调度策略
上面我们讲述了arena的数量限制。那么,一个很自然的问题就出现了:对于没有分配到arena的线程,如何进行内存管理呢?这就要引出arena的调度策略了。
假设我们现在有一个32位应用程序,它一共含有3个子线程,且只有1个cpu核心。那么,此时线程的数量是3+1=4个线程,而arena的最大个数是1(cpu核心数) * 2 (32位系统) = 2个。在这种情况下,glibc为了让每个线程都能在工作的时候分配到arena,会采用调度策略。假设线程间的malloc顺序如下:
- 主线程第一次调用
malloc时,直接使用main arena,没有竞争。 thread1和thread2第一次调用malloc的时候,都会为他们分配一个thread arena,没有任何的竞争。此时线程和arena之间也是一对一的关系。- 接下来,
thread3也调用了malloc。由于arena数量已经达到最大值,无法再给thread3分配一个arena,因此此时glibc将会让thread3尝试重用这几个arena(main arena, arena1, arena2): - 重用过程:
- 循环遍历来寻找可用的
arena,直到找到一个可用的arena为止。 - 若找到了一个可用的
arena,则尝试将它锁定,并将这个arena返回给线程使用、 - 若没有找到可用的
arena,那么thread3将会被阻塞,直到有一个可用的arena为止。
- 循环遍历来寻找可用的
- 在
thread3第二次调用malloc1的时候,thread3将会尝试使用最后一次使用的arena。假设上一次thread3使用了main arena,那么thread3将会尝试使用main arena。若main arena此时可用,那么thread3将会直接尝试使用main arena。若main arena此时不可用,那么thread3将会被阻塞,直到main arena可用为止。如此一来,main arena就在主线程和thread3之间实现了共享。
heap
在glibc的源代码中,主要有以下三种数据结构:
1 | |
1 | |
1 | |
注意:
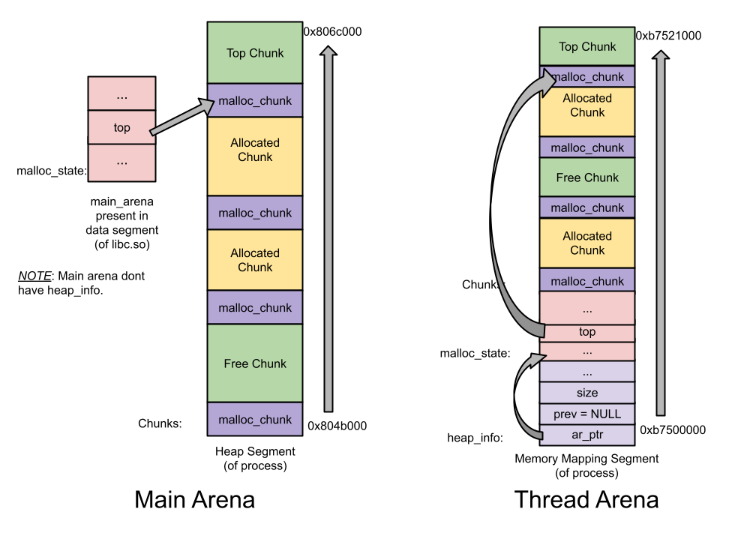
main arena没有多个heap段,也因此没有heap_info结构。当main arena的内存空间不够时,sbrk的堆结构将会被扩展(且是扩展了一段连续区域),直到遇到内存映射段为止。- 与
thread arena不同,main arena的arena header并不是sbrk堆段的一部分,它实际上是一个全局变量,并且被保存在libc中。数据段也是同样的。
main arena和thread arena的示意图如下:
只有一个heap的情况:
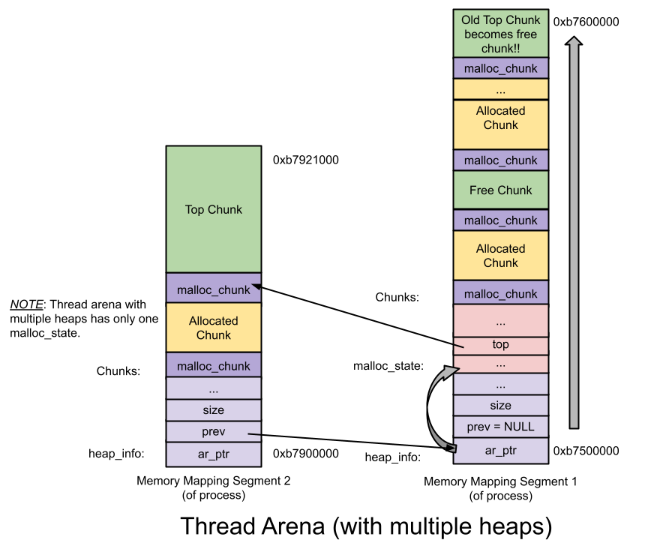
thread arena中含有多个heap的情况:
chunk
chunk是进行内存管理的基本单元,heap中的chunk可能有如下形式:
Allocated chunk(正在被使用)Free chunk(空闲)Top chunkLast Remainder chunk
其中,前面两种表示chunk的状态,而后面两种表示两种特殊的chunk。
Allocated chunk的结构如图所示:(每一行是一个数据,在32位下为4byte,64位下为8byte)
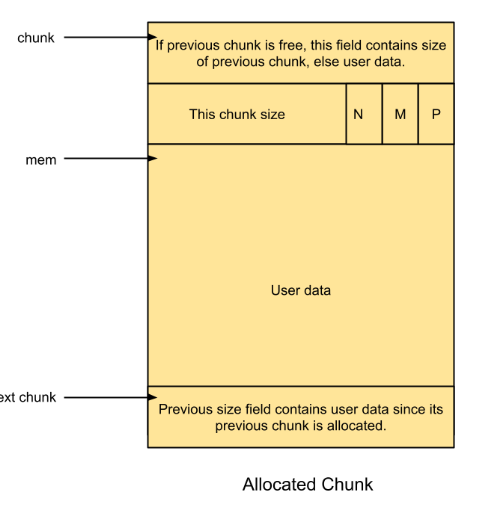
prev_size:实际上是最上面的数据。它不取决于当前chunk的状态,而是取决于与之相连的上一个chunk的状态。若上一个chunk的状态是free的,那么这个数据将会存放上一个chunk的大小,即prev_size;若上一个chunk的状态是allocated,那么这个数据空间将会作为上一个chunk额外可以存放的一点数据。
size:这是图中的第二行数据。可以看到,它包含chunk size和N/M/P三个数据位。这里是把本行的最后三个bit用作数据位(因为size最后三个bit本来肯定为0,因此这三个bit可以用来表示信息)。
其中:
N表示NON_MAIN_ARENA。表示当前的chunk是属于main arena的还是属于thread arena的。若属于thread arena,那么N=1。M表示IS_MMAPED。若当前chunk是由mmap创建的,那么M=1。P表示PREV_INUSE。若前一个chunk的状态是free,那么该标志位为0,若为allocated,那么该标志位为1。
Free Chunk的结构如图所示:
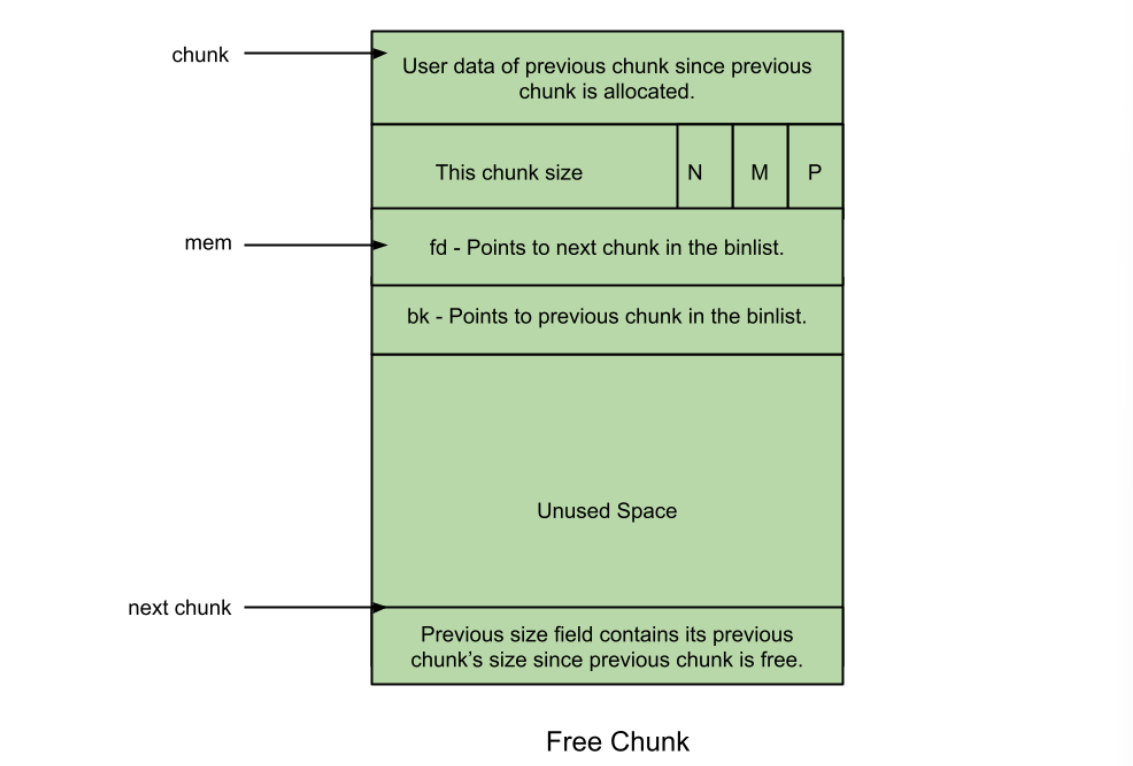
prev_size:当chunk的状态为free的时候,上一个chunk若也为free状态,那么两个chunk会被合并,因此不存在这种情况。因此,上一个chunk的状态此时一定为allocated,prev_size一定存放的是上一个chunk的数据。
size:和allocated状态的size位是一样的。
fd:前向指针,指向同一个bin中的下一个chunk。注意,不是指向物理内存相连的下一个chunk。
bk:后向指针,指向同一个bin中的上一个chunk。同上,不一定指向物理内存相连的下一个chunk。
bins
bins是维护被free掉的chunk的数据结构。基于chunk大小的不同,bins可以被分为如下形式:
Fast binUnsorted binSmall binLarge bin
bin在操作系统中由以下数据结构进行管理:
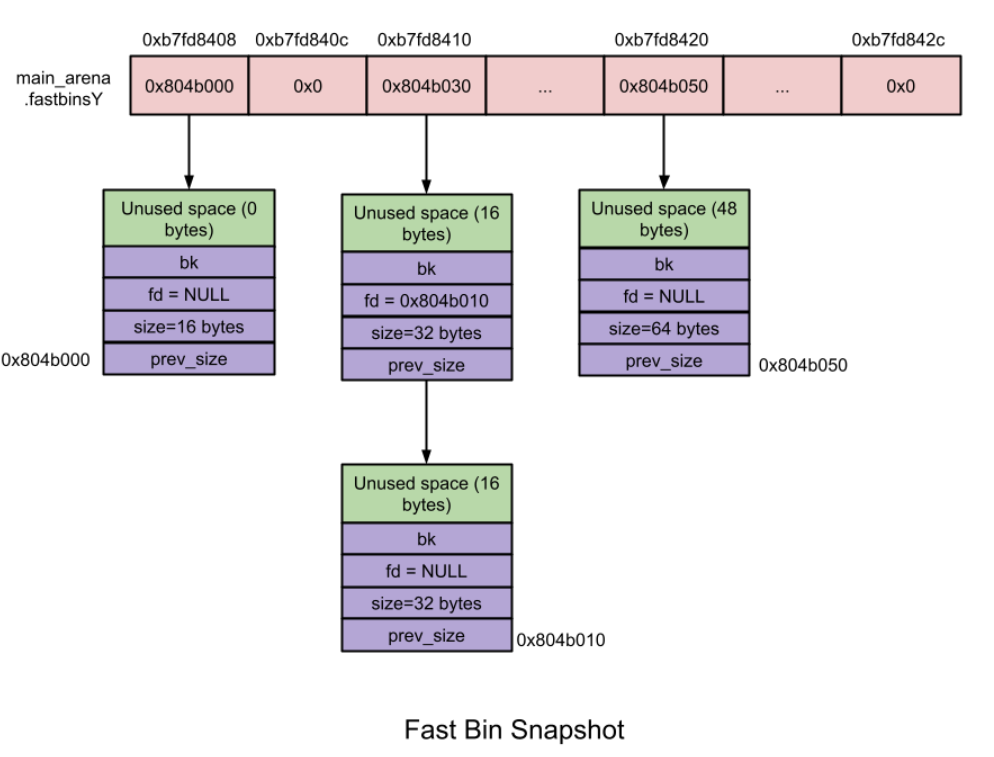
fastbinsY: 管理fastbin
bins: 管理unsortedbin、small bin和large bin。bins是个数组,长度为126,并且对应关系如下:
Bin 1-Unsorted binBin 2 - Bin 63-Small binBin 64 - Bin 126-Large bin
Fast bin
一共有
10个fastbin。每一个fastbin都是单链表,因为fastbin的chunk的存取操作都不会发生在链表的中间。由于fastbin是为了时间局部性原则,因此是后进先出(LIFO),存取操作都发生在链表头。在一个单链表内,
chunk的大小都是相同的。不同的单链表之间的大小差是根据系统的位数决定的,在32位下,差为8,在64位下的差则为16。例如在32位下,fastbin0的大小为16bytes,那么fastbin1的大小为24bytes。在
malloc初始化期间,最大的fastbin size被设置为64bytes,因此默认情况下16bytes-4bytes的chunk被分类为fastbin chunkfastbin不会合并。其他的bins中,两个相邻的空闲块可能会发生合并,但是fastbin是不会的,尽管这可能会产生内存碎片。这是因为这样做可以使得free的速度更快,fastbin就是为了操作系统能够更快地利用这些刚释放的chunk而设计的。fastbin的范围是由一个叫做global_max_fast的变量决定的,而这个变量在第一次malloc请求的时候还是空的。因此,当第一次使用malloc申请内存的时候,即使申请的内存大小属于fastbin,也会交给small bin来处理。
Unsorted bin
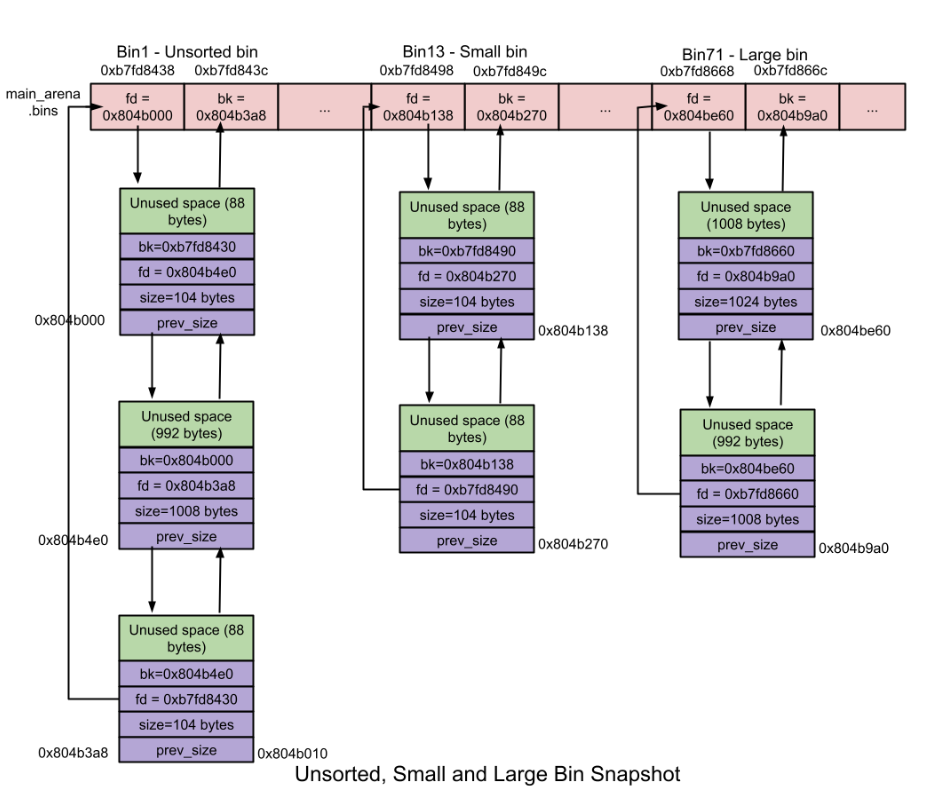
当大小属于small bin或者large bin的chunk被释放的时候,chunk也不会直接添加到对应的bin里面去,而是先被添加到unsorted bin,类似于fast bin,这样有利于时间局部性,因此略微加快了内存分配的速度,因为没有寻找合适的bin这个过程的时间。
- 一共有
1个unsorted bin。unsorted bin包含一个循环双向链表。如图所示。 chunk的大小:没有限制,任何一个大小的chunk都可以被添加到unsorted bin。
Small bin
低于512bytes(0x200)的chunk被称为small chunk。small bin的分配速度比large bin略快,但是比fastbin更慢。
- 一共有
62个small bin。每一个small bin都是一个双向循环链表,因此在small bin中的chunk都是通过unlink的方式进行解链的。添加到small bin的chunk将会被添加到链表头,但是删除操作会发生在链表尾(FIFO)。 - 不同
small bin之间的差值和fastbin是一样的。在同一个small bin中,chunk的大小是一样的,因此他们在循环链表中的顺序是置入small bin的顺序,不会发生别的排序。 - 合并:在
small bin中,若有两个相邻的chunk都是free的,那么他们会发生合并,成为一个空闲的chunk。合并操作减少了外部碎片,但是同时也减慢了free的速度。 malloc时:初始状态下small bin都为空,因此用户即使访问了一个属于small bin的chunk也是由unsorted bin来处理。在第一次调用malloc时,small bin和large bin都将被初始化,并且它们的bin都会指向自身,表示它们是空的。若small bin不为空,那么会取出对应small bin中的最后一个chunk给用户。free时:会检查相邻的上一个或者下一个chunk是否是free的,如果是,那么则会发生合并,并且将合并后的chunk添加到unsorted bin中。
Large bin
大于或等于512bytes(0x200)的chunk被称为large chunk,管理空闲的large chunk的数据结构叫做Large bin。
一共有
63个largebin。每一个large bin都是双链表,因为在链表头、链表尾以及任意位置都可能添加或者删除数据。和
small bin不同,在large bin中的chunk并不是同一个大小,因此在largebin中的chunk是按照降序排列的:最大的chunk在链表头,而最小的chunk在链表尾部。在这
63个largebin中,前32个largebin的最大chunk和最小的chunk之差为64bytes。例如第一个largebin的大小为512bytes-568bytes,而第二个largebin的大小就为576bytes-632bytes。接下来的
16个largebin相差512bytes。接下来的
8个largebin相差4096bytes。接下来的
4个largebin相差32768bytes。接下来的
2个largebin相差262144bytes。最后的
1个largebin包含其他所有的大小。合并:两个相邻的
free的chunk会被合并为一个chunk。malloc时:未初始化时,与small bin过程相同。初始化完成后,若用户请求的
chunk大小要小于large bin中最大的chunk,那么largebin会进行遍历来找到大小相等或者接近的chunk。找到之后,这个chunk会被进行切割成两个部分:第一个部分返回给用户,第二部分作为Remainder chunk添加到unsorted bin。若用户请求的
chunk大小要大于large bin中最大的chunk,那么largebin则需要寻找一个更大的largebin。但此时若直接遍历查看往后的largebin是否有满足条件的largebin太慢了,因此有一个叫做binmaps的东西用来记录哪些largebin为空,并以此找到下一个不为空的largebin来重复以上的遍历方法。一旦找到了,同上。若没有找到,那么会使用top chunk来分配合适的内存。free操作:和small bin相同。
Top Chunk
Top Chunk是在一个arena的顶端部分的chunk,它不属于任意的bin。Top chunk的作用是在所有bin中都没有空闲的chunk时来处理用户的malloc请求。
若top chunk大小要大于用户请求大小,那么top chunk会被分为以下两个部分:
- 用户请求,返回给用户
Remainder chunk,Remainder chunk会成为新的top chunk。
若top chunk大小要小于用户请求大小,那么top chunk会通过sbrk(main arena)或者mmap(thread arena)的系统调用方式来进行扩展,取决于是main arena还是thread arena。
Last Remainder Chunk
Last Remainder Chunk是一个在Unsorted bin中的特殊chunk。它会有两个地方产生作用:
用户请求的
size输入small bin,但small bin中对应的bin为空,而略大于这个chunk对应的值的small bin非空,那么就从这个small bin上面取出一个chunk,分为两部分,一部分给用户,而另一部分形成Last Remainder Chunk返回到Unsortedbin中。这也就是产生。若处理用户的请求时,
fastbin和smallbin均分配失败,那么会尝试从unsorted bin中分配。如果满足以下条件:- 申请的
size在small bin范围内 unsortedbin仅有一个free chunk- 且为
last remainder chunk - 正好满足用户请求的
size
那么,就将
last remainder chunk分成两部分,一部分返回用户而另一部分作为新的last remainder chunk插入到unsorted bin中。- 申请的
last remainder chunk主要是利用了内存分配的局部性来提高连续malloc的效率(试想有一连串的small request)。
至此,Understanding glibc malloc这篇文章的个人翻译也就结束了,希望能通过这篇文章为起点,学习到glibc的更多知识^ ^。